Watermark¶
约 4027 个字 预计阅读时间 20 分钟
Properties¶
- <1> Blind vs Informed
- Blind Watermarking 盲水印
- 检测时不需要知道原始 work,也称公开水印系统(Public Watermarking System)
- 常用于 Copy Control 等应用场景
- Informed Watermarking 知情水印
- 检测时需要访问原始 work,也称私有水印系统(Private Watermarking System)
- 常用于 Transaction-Tracking 等应用场景
- Blind Watermarking 盲水印
- <2> False Positive 假阳性 or 误检率
- 指 Detector 错误地在不存在水印的 work 中检测到了水印
- 根据不同应用场景,使用不同方式进行误检率计算
- Fixed Work + Random Watermarks:常用于 Transaction-Tracking
- Fixed Watermark + Random Works:常用于 Copy Control
- <3> Robustness
- 水印通常需具备在常见信号处理操作后仍能被可靠检测的能力
- 对于图像,可能是过滤、压缩、几何变形、信号失真
- 对于视频,可能是录制、帧率变换
- 对于音频,可能是混音
- 某些情况下,过于鲁棒的水印反而是不必要的。脆弱水印设计为对任何修改都非常敏感,常用于内容认证(Authentication),一旦作品被篡改,水印就会被破坏,从而实现完整性验证
- 水印通常需具备在常见信号处理操作后仍能被可靠检测的能力
Communication-Based Models¶
要在信道中进行传输,我们需要将 Message 转换为 Signal。然而,在信道传输过程中,难免会遇到噪音或者信号衰减。基于此,我们构建出如下 Communication Systems:
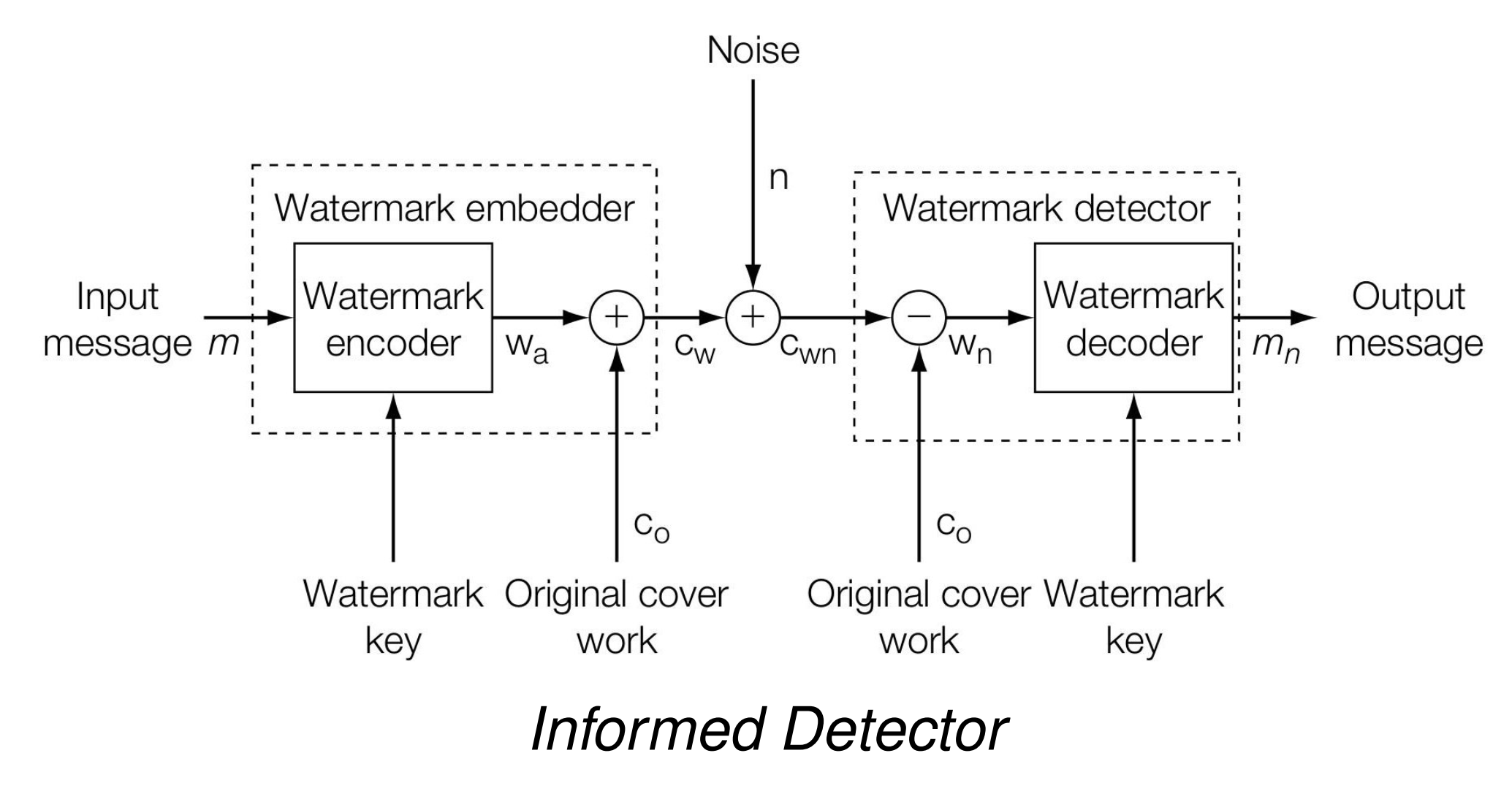
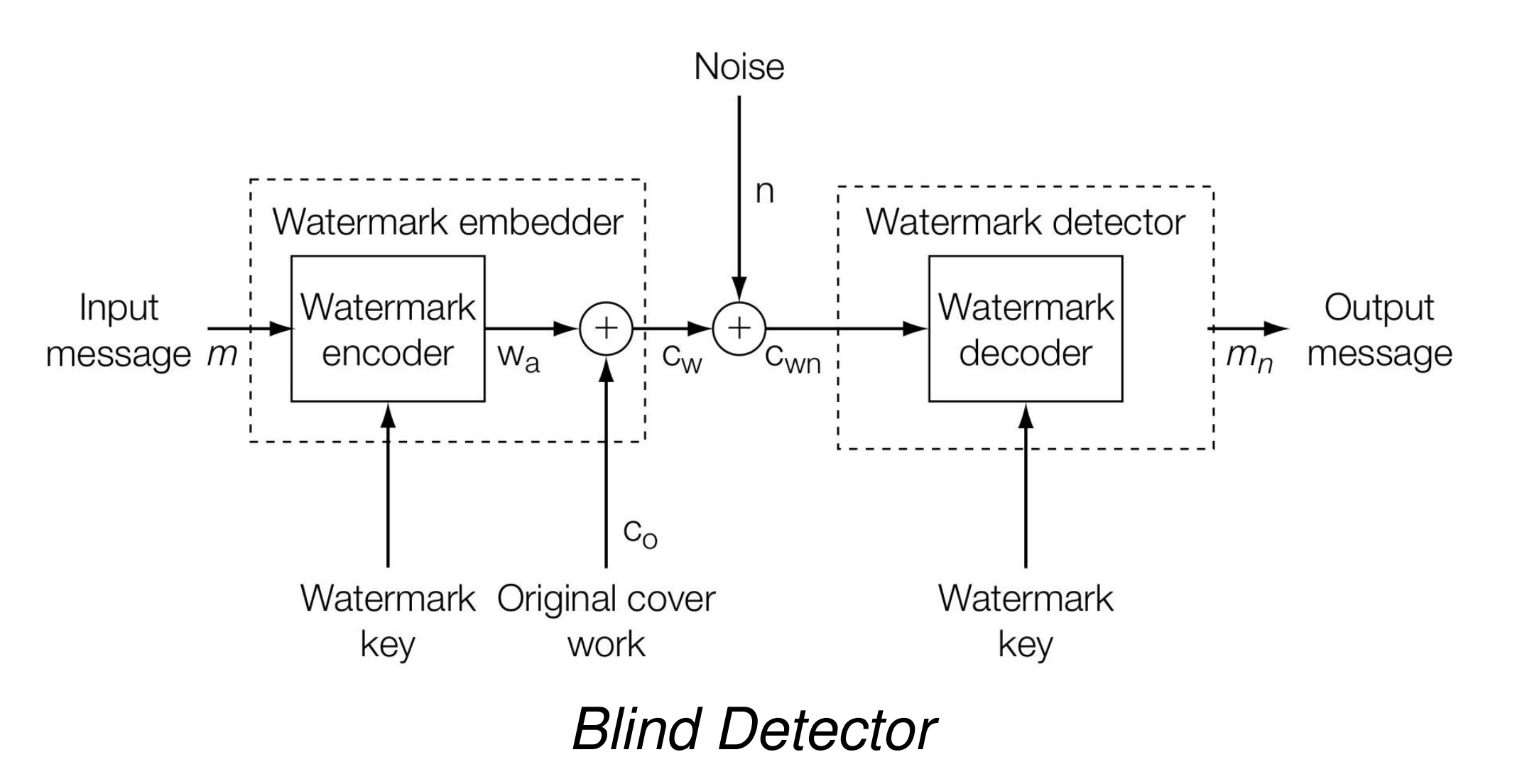
在不考虑信号衰减的情况下,最终接收者 decoder 收到的信号 \(c_{wn}\) 如下:
Watermark Key 是可选项,用于先将 Input Message 加密再嵌入 Work 中,实现 Encryption
E_BLIND 模型属于 Blind Embedding 的一种。我们先考虑 message \(m\) 只有 1 bit,即 \(m\in 0,1\),此时我们称 Key 为 Reference Pattern,记为 \(w_r\),它的长度为 \(N\),与 work 的像素/系数大小相同:
- <1> Encoding into Message Pattern:
- \(w_{m} = (2m-1) w_{r}\)
- 当 \(m=1\) 时,\(w_{m} = w_{r}\)
- 当 \(m=0\) 时,\(w_{m} = -w_{r}\)
- <2> Modulate to Added Pattern:
- \(w_{a} = \alpha w_{m}\)
- \(\alpha\) 称为控制强度因子,越大嵌入越强,但失真越大
- <3> Embedding
- \(c_{w} = c_{o} + w_{a}\)
- <4> After Transmission
- \(c = c_{w} + n\)
- \(c= \alpha (2m-1) w_{r} + c_{0}+ n\)
检测方案采用 D_LC,我们并不需要原始图像,而是直接将 \(c\) 与 \(w_r\) 做归一化点积,该统计量记作 \(z_{lc}\)。绝对值越大,表示 \(c\) 和 \(w_r\) 的线性相关性越强:
统计上,干扰项 \((c_{o}+n)\) 通常与 \(w_r\) 不相关,因此它们之间的点积均值为 0,此处记为 \(\varepsilon\)
图像通常在低频上具有更多信息,因此如果 Reference Pattern \(w_r\) 也是低频的,可能会导致 \(\varepsilon\) 过大,从而出现 worse fidelity。
为了检测 \(m\),我们设置一个阈值 \(\tau_lc\):
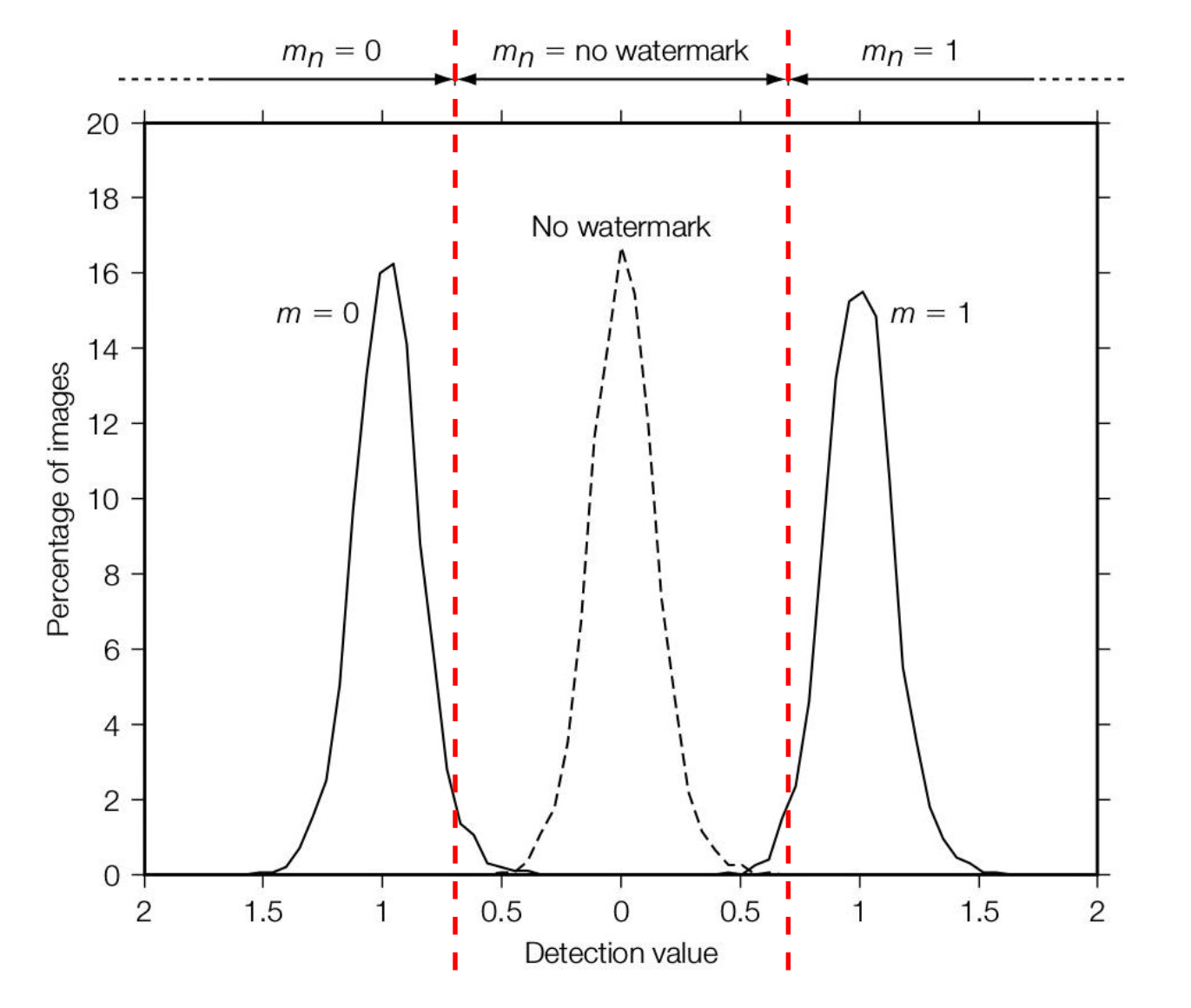
中间区域称为拒绝区,可以看到,当 \(\alpha\) 极小时,几乎不能正确检测到水印
在实际应用中,我们通常会对 \(w_r\) 进行归一化处理,要求它的方差为 1,即:
由于 \(w_r\) 的均值 \(\mu_{w_{r}}\) 通常接近 0,我们可以认为统计量的期望值近似于:
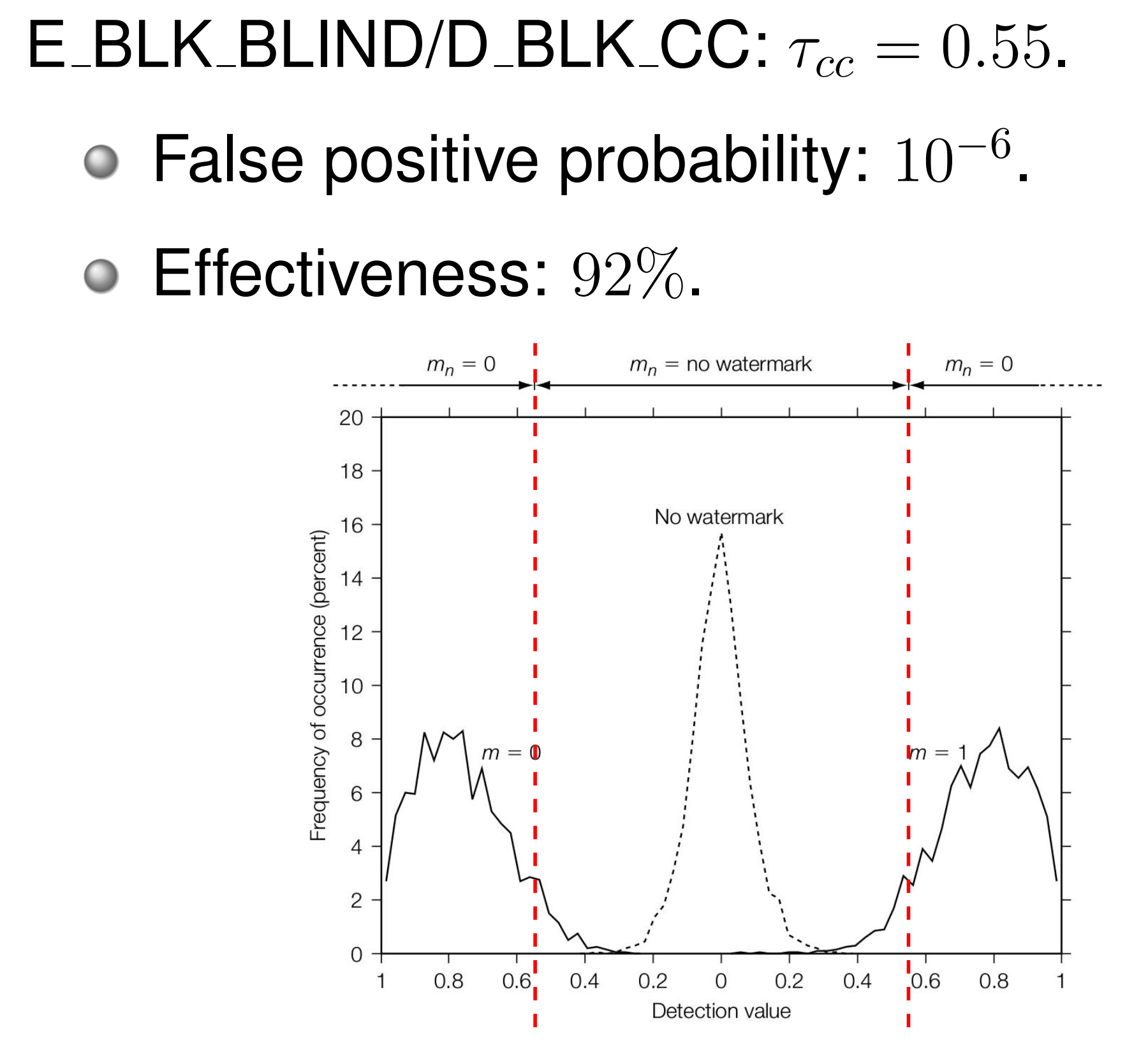
给出一个实验数据
- 2000 个 Images:\(\alpha = 0\),no watermark
- 2000 个 Images:\(\alpha=1, m=1\)
- 2000 个 Images:\(\alpha=1, m=0\)
- 设置阈值 \(\tau = 0.7\)
- 此时 False Positive Rate 为 0.01%,即图中虚线部分延申到左右两侧的部分(虽然并没有画出来)
- 此时 Effectiveness 为 98%,即有水印的这 4000 个图中,正确检测到有水印的部分
另外,在嵌入端,嵌入器可以提前决定这个图像改用多大的 \(\alpha\) 合适。我们使用 \(z_{lc} (c_{w} , w_{m})\) 作为基准来计算,要求其值要略大于 \(\tau _{lc}\),设置 margin \(\beta \gt 0\):
这种自适应 \(\alpha\) 能够更好地平衡 Fidelity 和 Robustness。对于纹理复杂、能量高的图像使用较大 \(\alpha\);对于平坦、敏感的图像则使用更小的 \(\alpha\),避免视觉失真。它的表现可能如下:
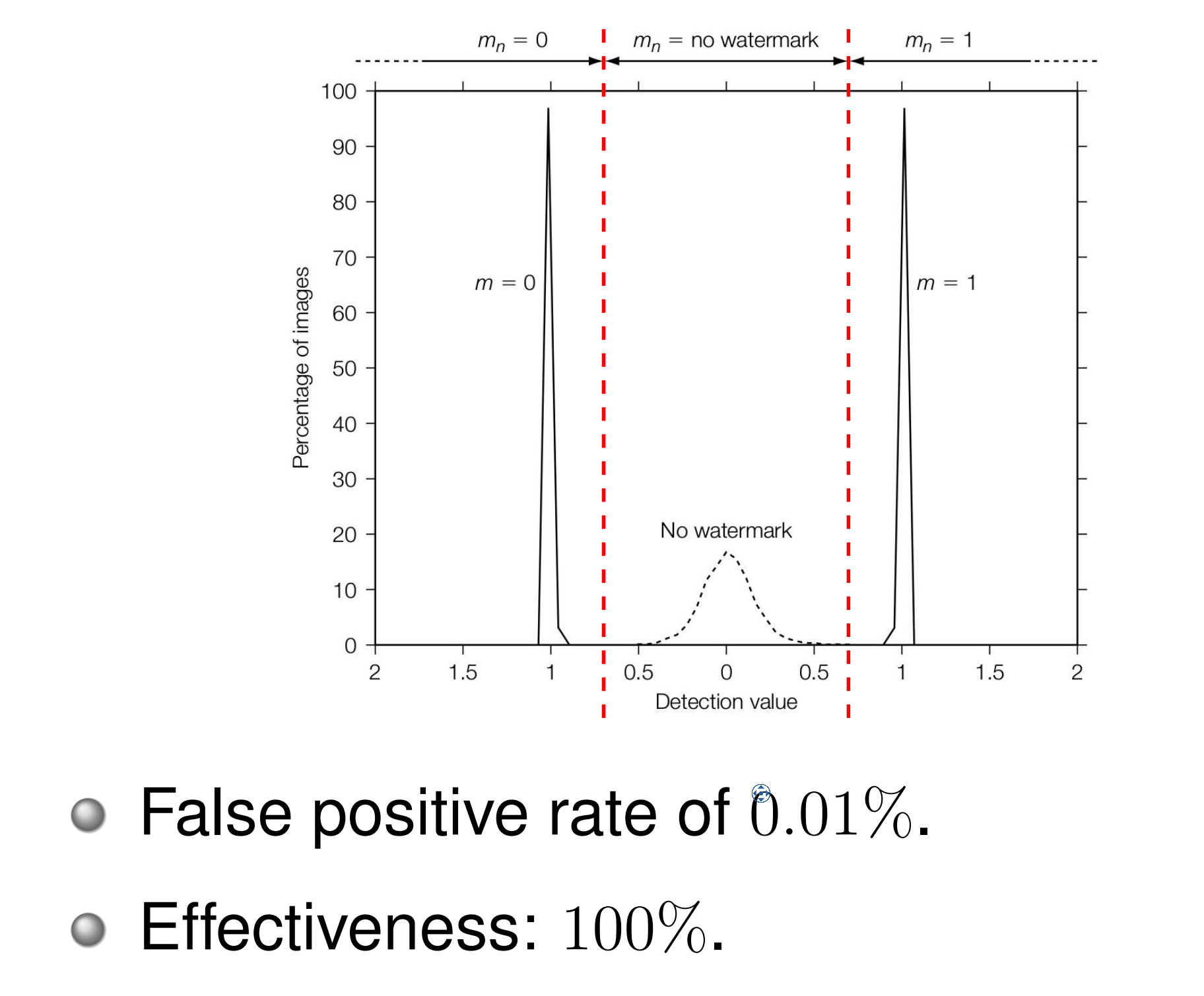
当然,计算出的 \(\alpha\) 也可能过大,导致牺牲 fidelity。
Geometric Models¶
接下来我们使用几何模型来抽象描述数字水印系统,其核心思想是将多媒体作品(图像、音频、视频)看作是高维空间中的一个点,水印操作则是对这个点的移动。
- Media Space 媒体空间
- 原始的多媒体作品所在的空间,每个点都对应一个完整的 work
- 对于 N 个像素的灰度图像,是一个 N 维空间
- 对于 N 个像素的 24-bit RGB 图像,是一个 24N 维空间
- 对于 N 帧的视频,维度则更加高
- Marking Space 标记空间
- 是 Media Space 的投影版本或失真版本,水印的嵌入和检测通常在 Marking Space 进行
- 例如直方图
我们为 Fidelity 近似建模:
- Just Noticeable Difference (JND):刚好可察觉的差异(最理想但难计算)
- 均方误差 (Mean Square Error, MSE) 近似:
- \(D_{mse}(c_{1} ,c_{2}) = \frac{1}{N} ||c_{1} - c_{2} ||^{2}\)
- 信噪比 (SNR) 近似:
- \(D_{snr}(c_{1} ,c_{2} ) = \frac{||c_{1} - c_{2} ||^{2}}{|| c_{1} ||^2}\)
无论是哪种近似方法,一个可靠的置信区间都是以 original work 为球心的一个球。
而从 Detector 视角来看,我们希望水印能够被检测到,即有 \(\tau_{lc} \lt |z_{lc}(c,w_{r})| = |c\cdot w_{r}|/ N\)。在几何空间上,该不等式就相当于以 \(w_r\) 为坐标轴,work \(c\) 的该轴值要大于一定值。我们同时将该轴与置信区间绘制,则它们的重叠部分则认为是一个成功的水印版本:
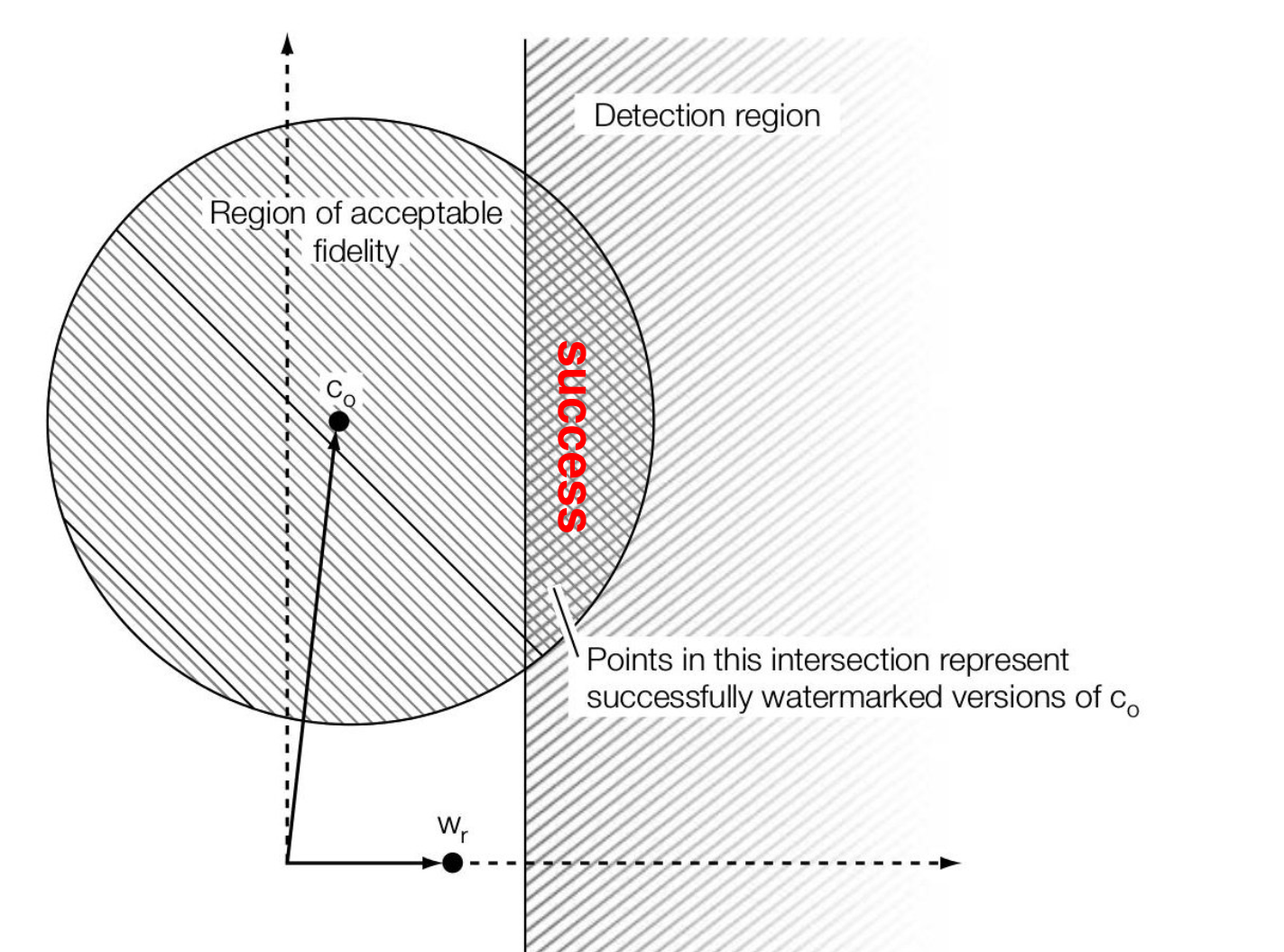
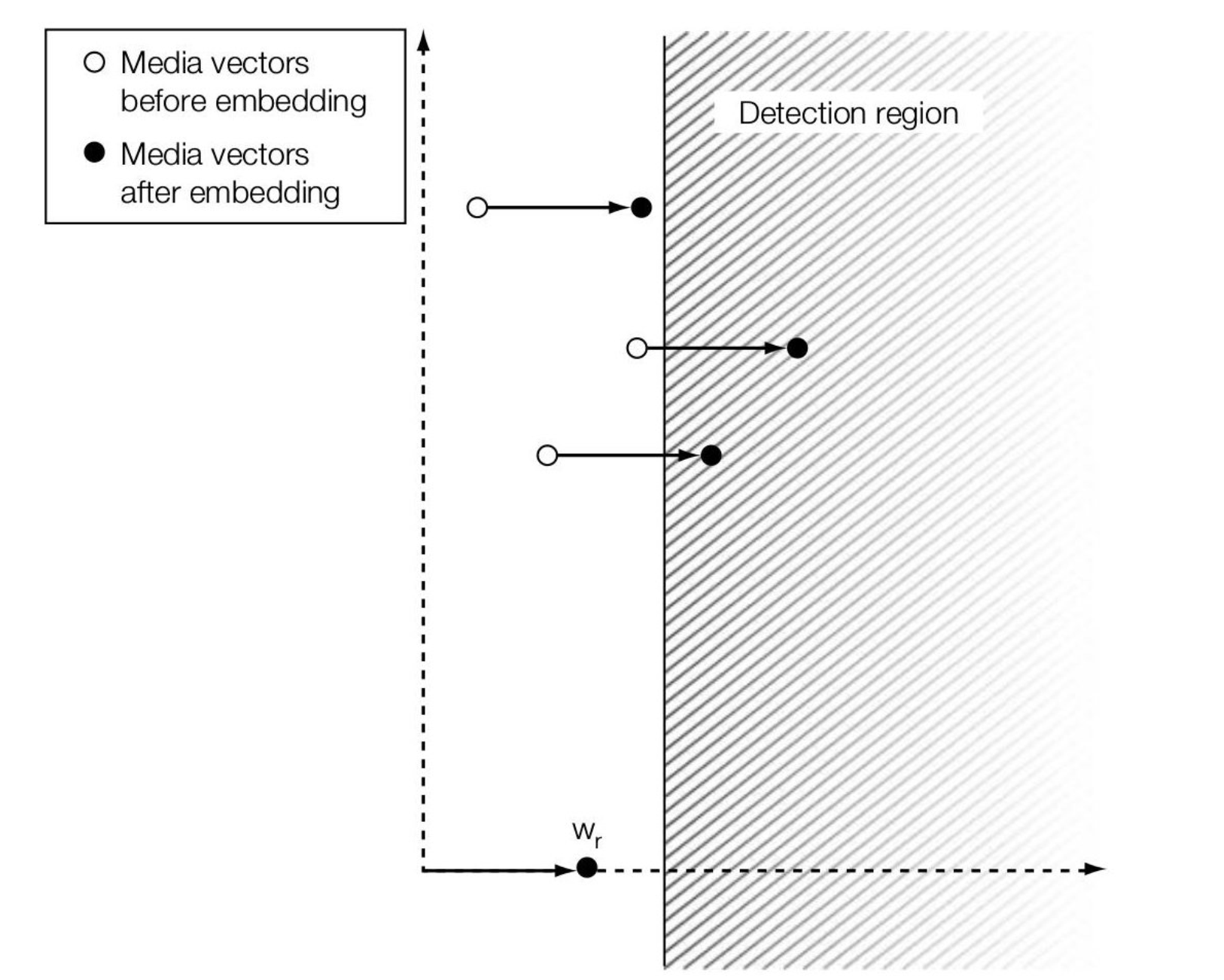
再从 Embedder 视角来看,如果采用 E_BLIND,则嵌入后的作品是有可能出现在 Detection Region 之外的(\(\alpha\) 为固定值);而另一种方法 E_FIXED_LC 则要求输出只会落入 Detection Region 之内,从而保证了 100% 的 effectiveness,此时根据余量 \(\beta\),我们为每个 cover 都设置一个专门的 \(\alpha\):
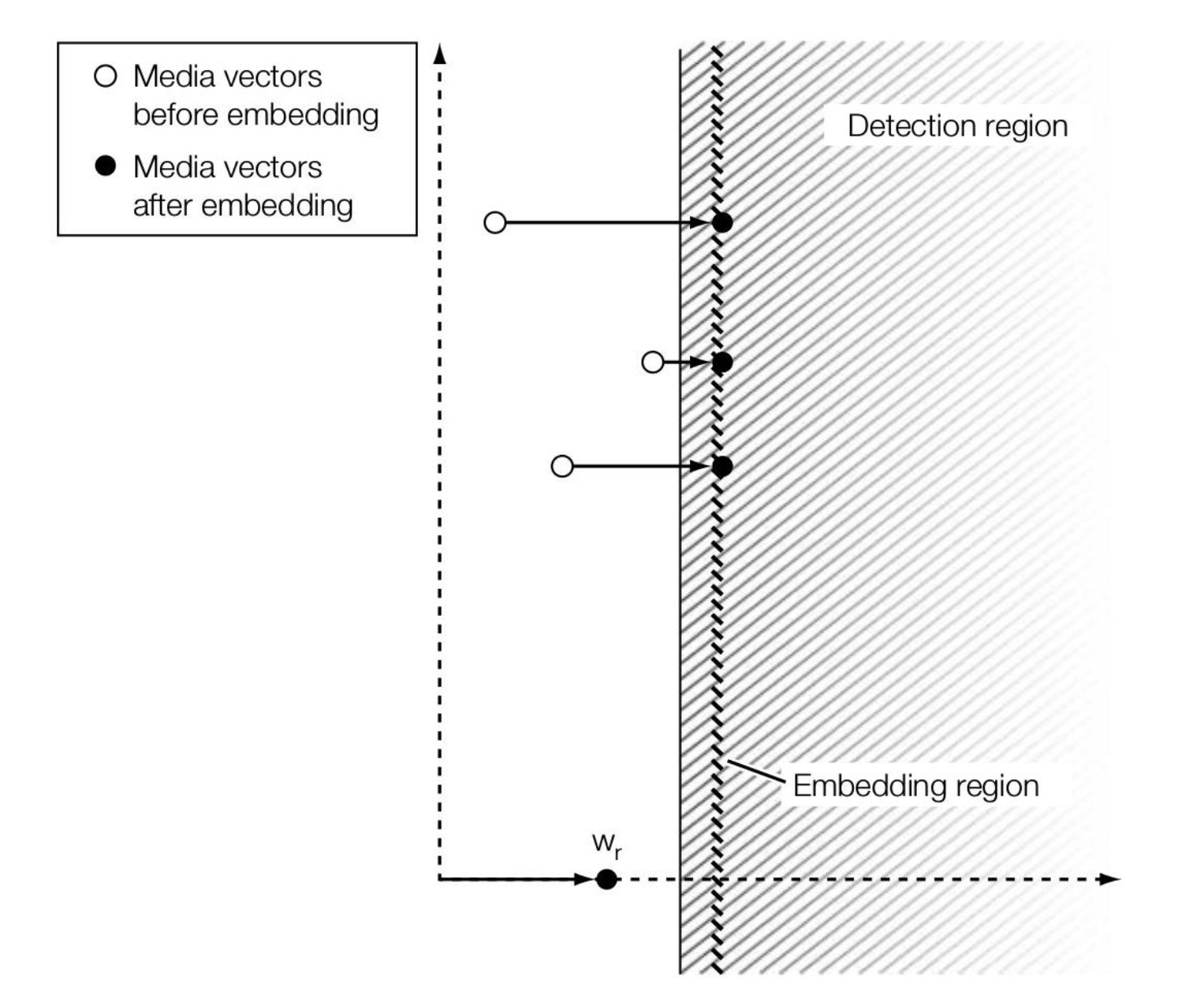
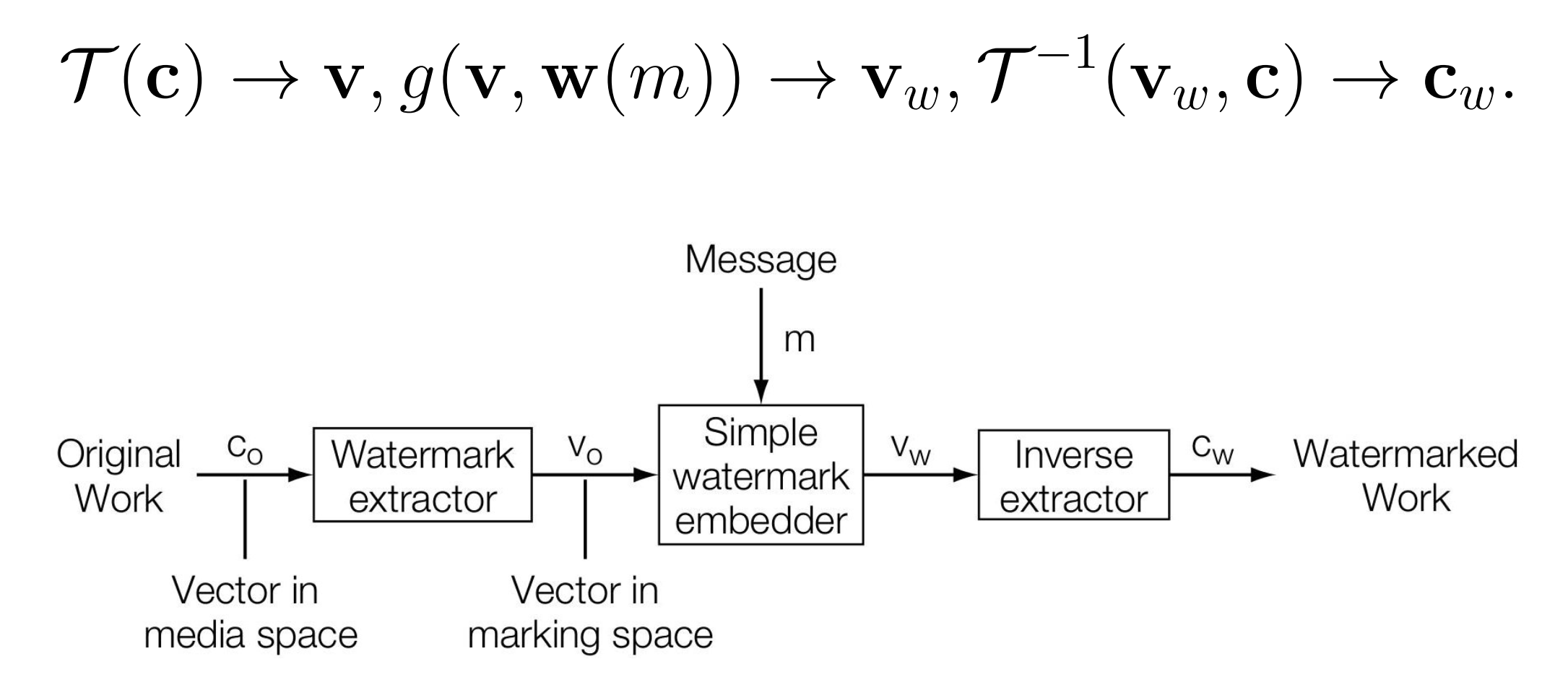
如果我们直接在 Midea Space 进行嵌入,则方程为:
但是如果我们在 Marking Space 进行嵌入,则可以使用相比 \(f\) 更简单的 \(g\) 进行操作:
此时在 Embedder 方和 Detector 方进行操作流程为:
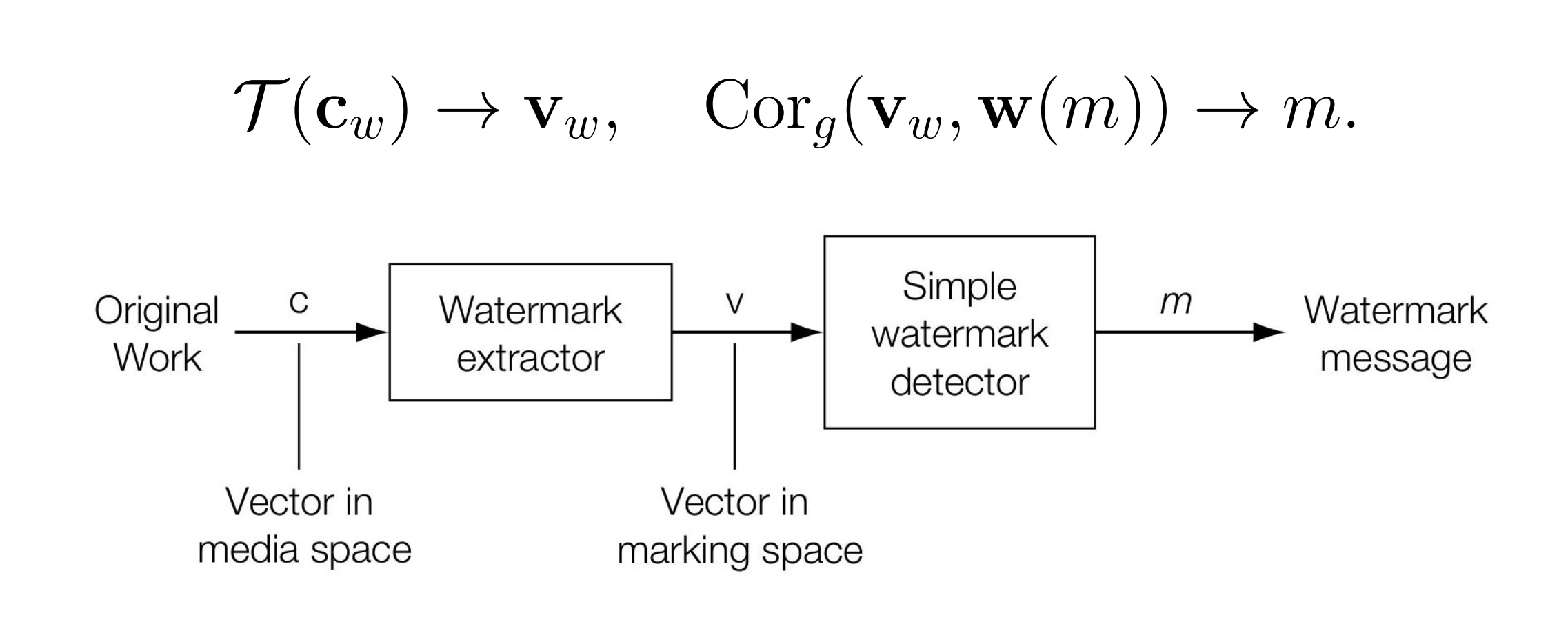
核心思想就是通过降维来获得更低的开销,同时得到更好的分布特性
一个典型案例是将一个 \(128\times 192\) 的原始图片按照每个格子都是 \(8\times 8\) 来分割,总共得到 \(384\) 个小格子,然后对所有小格子的灰度值取均值:
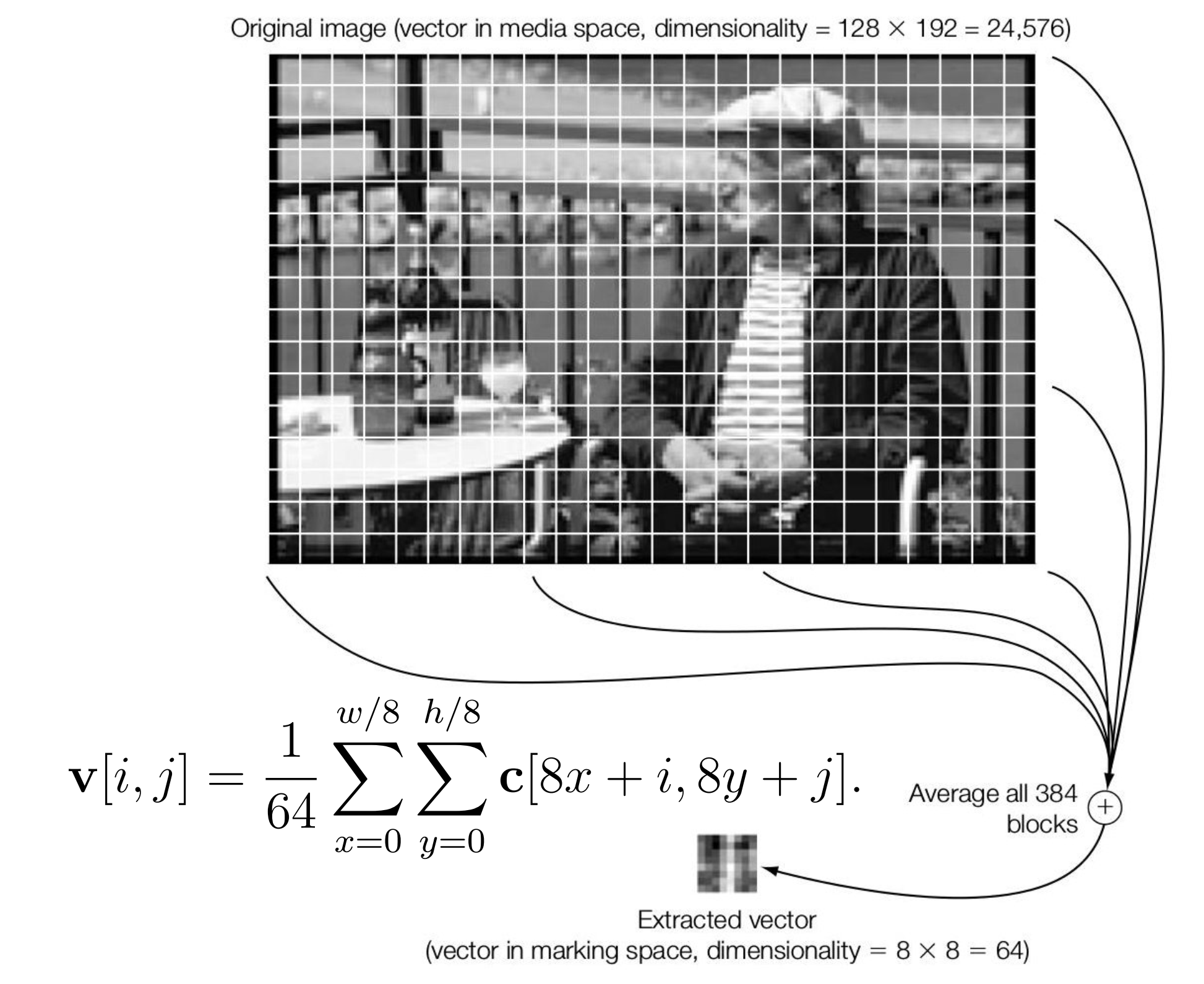
图上的 \(\frac{1}{64}\) 其实是 \(\frac{64}{wh}\),即 \(\frac{1}{384}\)
对于 Marking Space 的 Detector,我们可以接着使用 D_LC,但是更推荐使用会进行归一化处理的 D_CC(Correlation Coefficient):
对于 Marking Space 的 Embedder,可以使用 E_FIXED_LC 这种自适应 \(\alpha\),但是对 D_CC 来说较为复杂;也可以简单使用 E_BLIND,设置 \(\alpha=1\),即 \(v_{w}= v_{o} +w_{m}\)。在如上例子的情况下,水印转换回媒体空间时的公式如下:
Performance
Modeling By Correlation¶
在 Detector 端,我们有基于相关性的三种检测器:
- Linear Correlation 线性相关
- \(z_{lc} (v,w_{r})= \frac{1}{N}v\cdot w_{r}\)
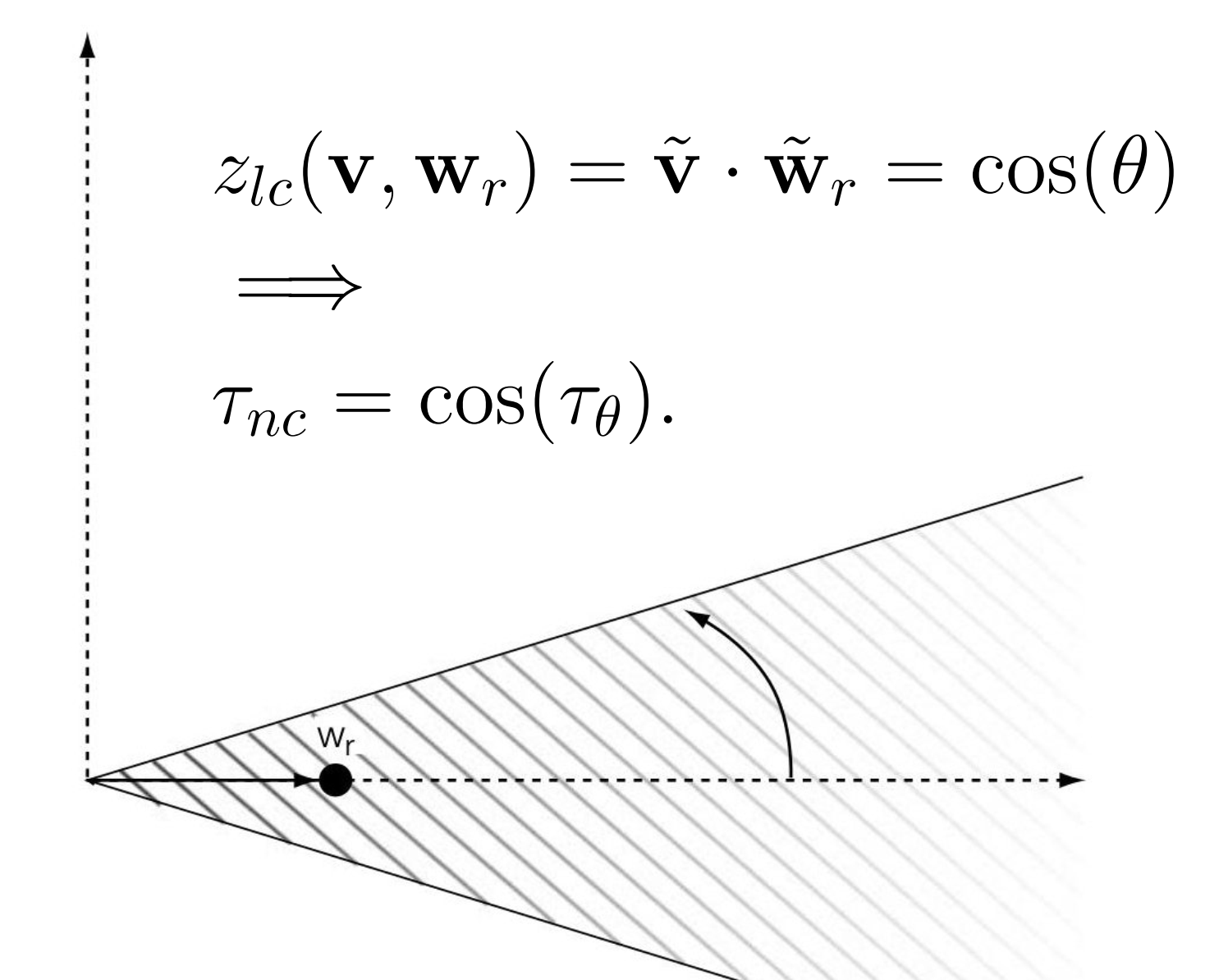
- Normalized Correlation 归一化相关
- \(\tilde{v}=v / ||v||, \tilde{w_{r}} = w_{r} / ||w_{r}||\)
- \(z_{nc}(v,w_{r})= \tilde{v} \cdot \tilde{w_{r}} = \cos {\theta}\)
- Correlation Coefficient 相关系数
- \(\tilde{v} = v - \bar{v}, \tilde{w_{r}} = w_{r} - \bar{w_{r}}\)
- \(z_{cc} (v,w_{r}) = z_{nc} (\tilde {v}, \tilde{w_{r}})\)
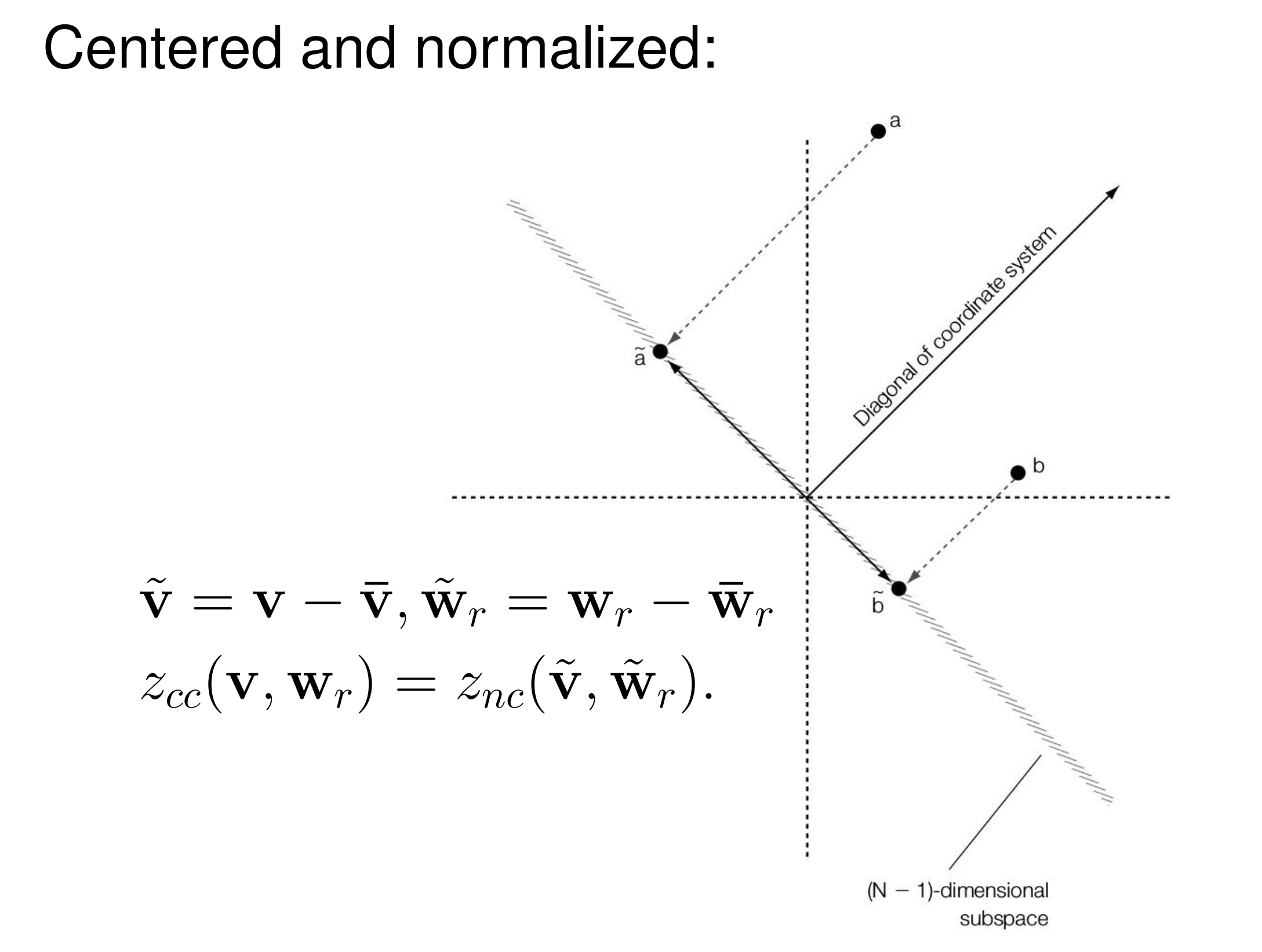
注意到,对于 D_CC,\(\tilde{v} = v-\bar{v}\) 一定关于 \(1_{N\times N}\) 垂直,即 \(\tilde{v} \cdot 1_{N\times N} = 0\),那么关于相关系数所有的向量都在 \(1_{N\times N}\) 的垂直平面上操作,相当于从 N-space 投影到了 (N-1)-space,实现了维度减小。
Message Coding¶
之前我们尝试了添加了 1-bit Message 的水印,接下来我们尝试编码更加复杂的 Message。
一种最直接的方法是采用 Direct Message Coding,即为每一个消息 \(m\in \mathcal M\) 对应唯一一个预定义的水印向量 \(w(m)\in \mathcal W\),二者之间是单射关系,且 \(|\mathcal M| = |\mathcal W|\)。
检测器在检测时,使用最大似然值选择相关性最高的水印向量 \(w(m)\)。因此,我们要求不同水印向量之间的负相关性越强越好,例如之前设计的 \((2m-1) = \{-1,1\}\)。
在 Multisymbol Message Coding 中,直接编码效率较低,例如对于 16-bit 的 information 需要 \(2^{16}\) 个编码。因此,我们改用符号序列,给出 Alphabet \(\mathcal A\) 和 Length \(L\) 的序列:
- 可以编码 \(|\mathcal A|^L\) 个不同的 Messages
- 对于 Direct Message Coding,\(L=1\)
- \(|\mathcal A|^{1}=65536\) for direct message coding
- \(|\mathcal A|^{8} = 65536\) for 4-symbol 8-length coding
- 此时每处只需要比对 4 个符号,比对 8 处即可
序列的复用方式有 Time/Space/Frequency/Code-Division 等,我们主要了解码分复用,设计一张 \(L\times |\mathcal A|\) 的 Reference Marks 表 \(\mathcal W_{\mathcal {AL}}\):
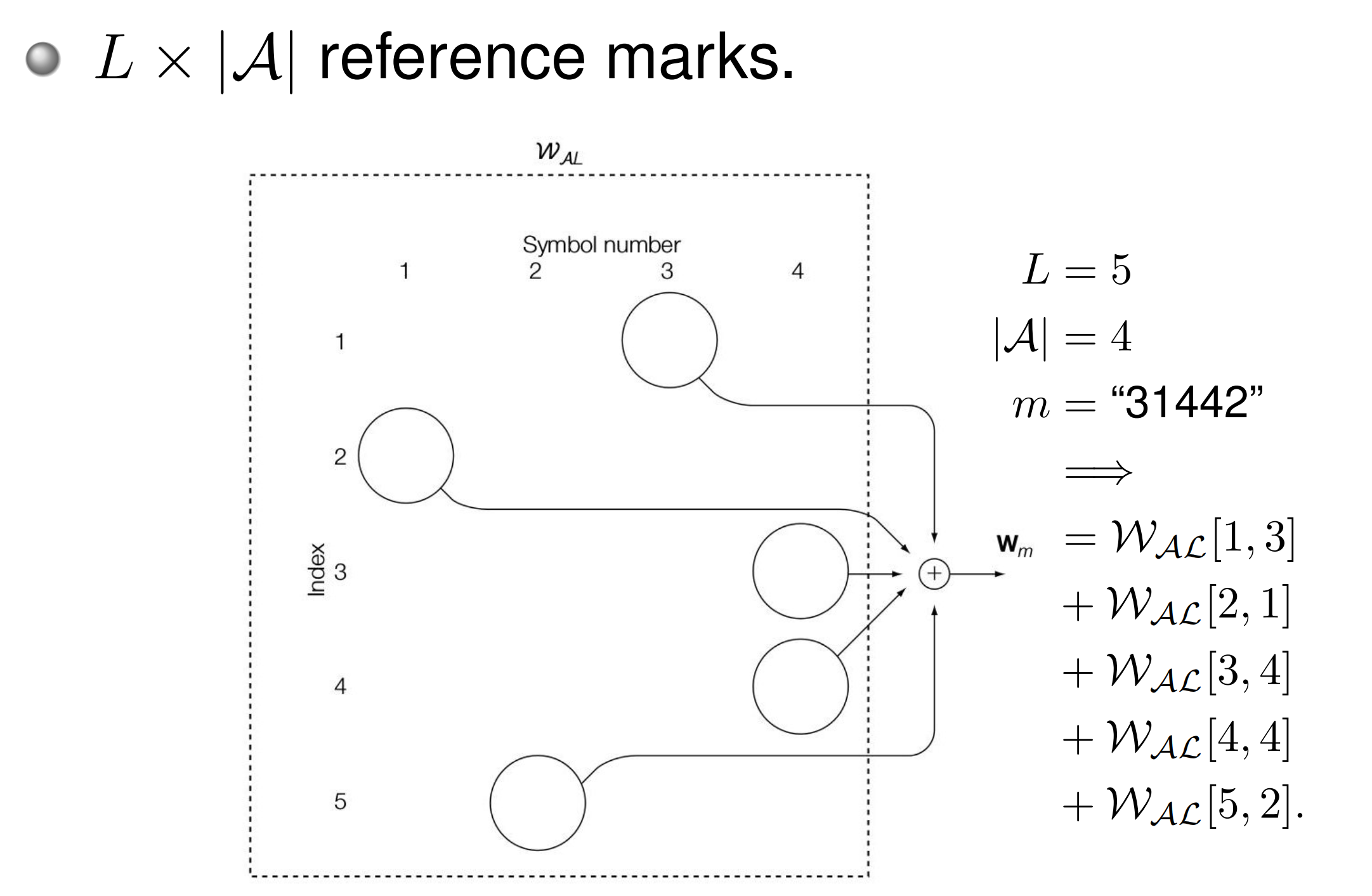
我们最终的 \(w_m\) 是所有对应位置的 Reference Mark 的相加,因此在实现上,我们要尽量满足:
- 不同序列位置的符号不相关,几乎正交
- \(\mathcal W_{\mathcal {AL}}[i,a ] \cdot \mathcal W_{\mathcal {AL}}[j,b] = 0,\ \text{if } i\ne j\)
- 同一序列位置的符号负相关,便于区分
- \(\mathcal W_{\mathcal {AL}}[i,a ] \cdot \mathcal W_{\mathcal {AL}}[i,b] = -1,\ \text{if } a\ne b\)
E_SIMPLE_8/D_SIMPLE 8 是其一个具体的实现,它是一个 8-bit 的 Binary String,即 \(|L|=8, |\mathcal A|=2\)
Error Correction Coding¶
不同 \(w_m\) 的相关性有可能很大。在 \(L\) Sequence 时,如果两个 Message 有 \(h\) 个不同的符号,则它们编码的内积为 \((L-2h)N\),例如:
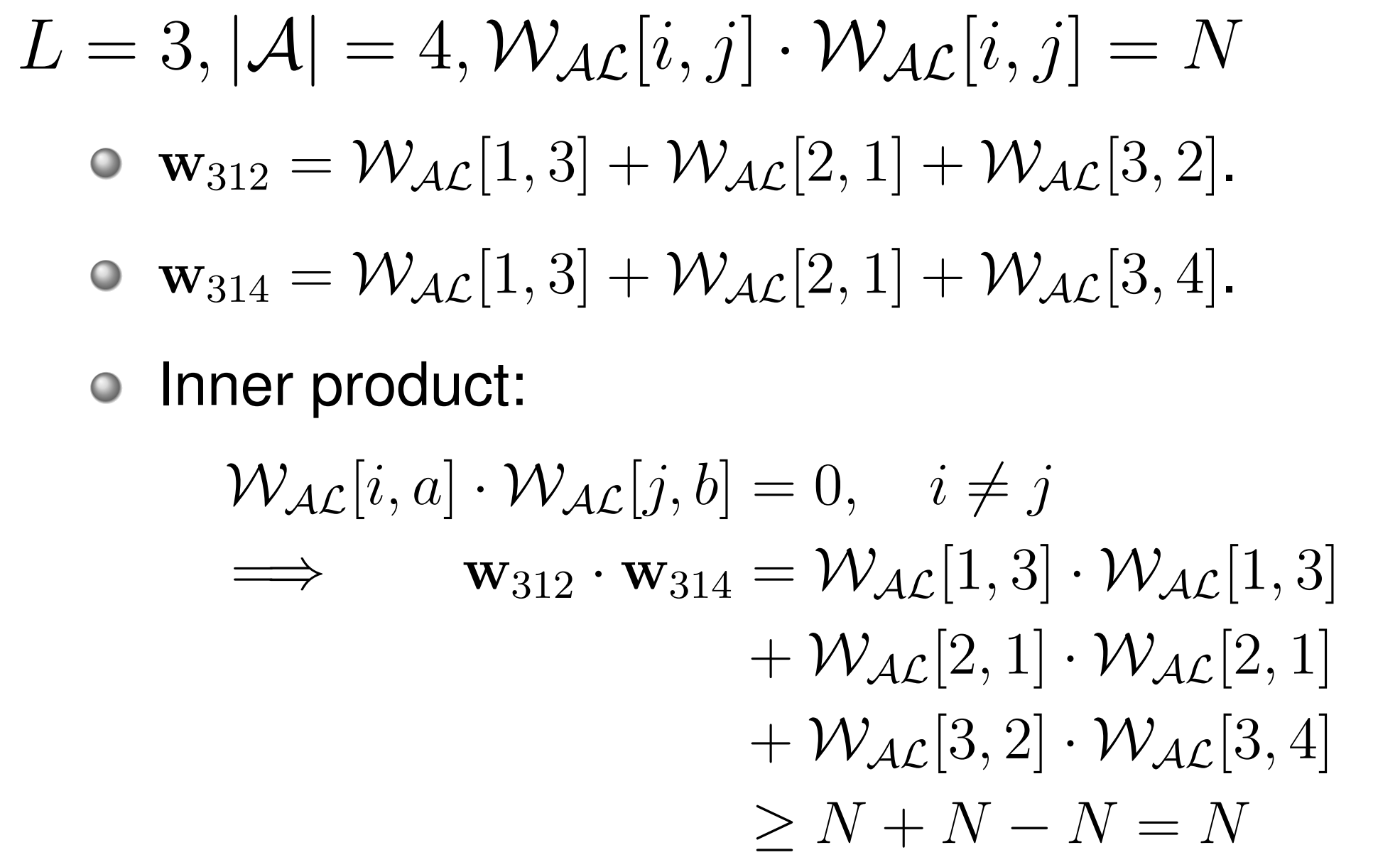
此时如果因为某些噪音的原因,可能会出现一些无法确定原来是什么编码的信号。我们可以设计一些 Error Correction Code(ECC)来减缓这一症状:
- Method 1: 增大序列长度 \(L\)
- 例如使用海明编码,对于 4-bit Message,为了纠正 1-bit 错误,码字空间 \(\mathcal S\) 为 7-bit,其中有 4-bit 信息位和 3-bit 校验位(\(2*1+1=3\))
- 海明编码还需要满足 \((m+r+1)\le 2^r\)
- 各个编码的海明距离起码为 3,意味着不同编码的内积最大为 \((7-2*3)N=N\),相比于原先的 Length 4,1-bit difference 的 \((4-2*1)N=2N\) 小了不少
- 例如使用海明编码,对于 4-bit Message,为了纠正 1-bit 错误,码字空间 \(\mathcal S\) 为 7-bit,其中有 4-bit 信息位和 3-bit 校验位(\(2*1+1=3\))
- Method 2: 扩大符号表 \(\mathcal A\)
- 例如使用 Trellis Codes,它使用状态机的路径来对一串字符进行编码
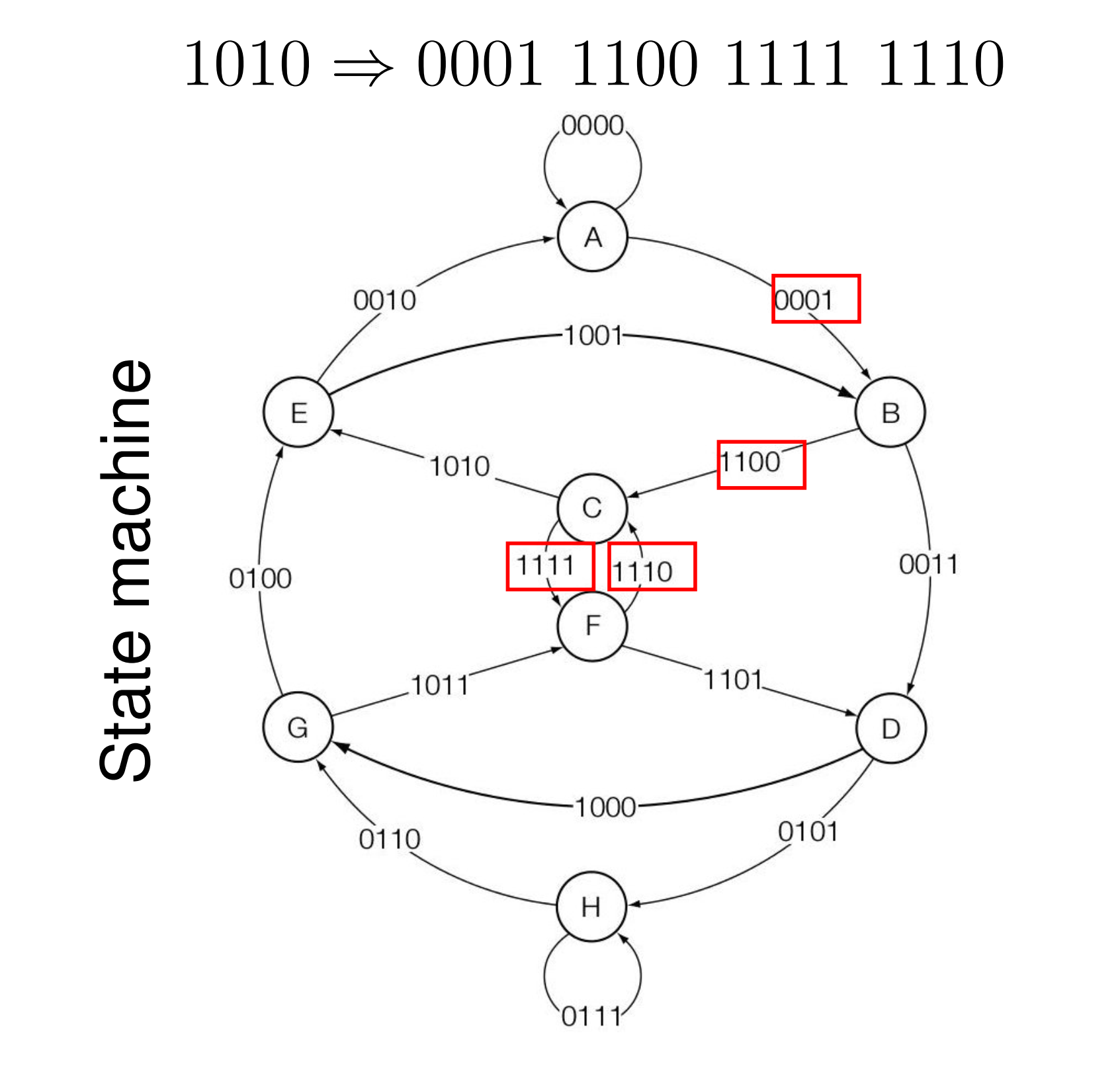
此处我们给出一个较为简单的 Trellis Codes,从初始状态 00 开始,读到什么就将其添加到当前状态后面,然后将这三个符号进行运算得到输出 \(p\):
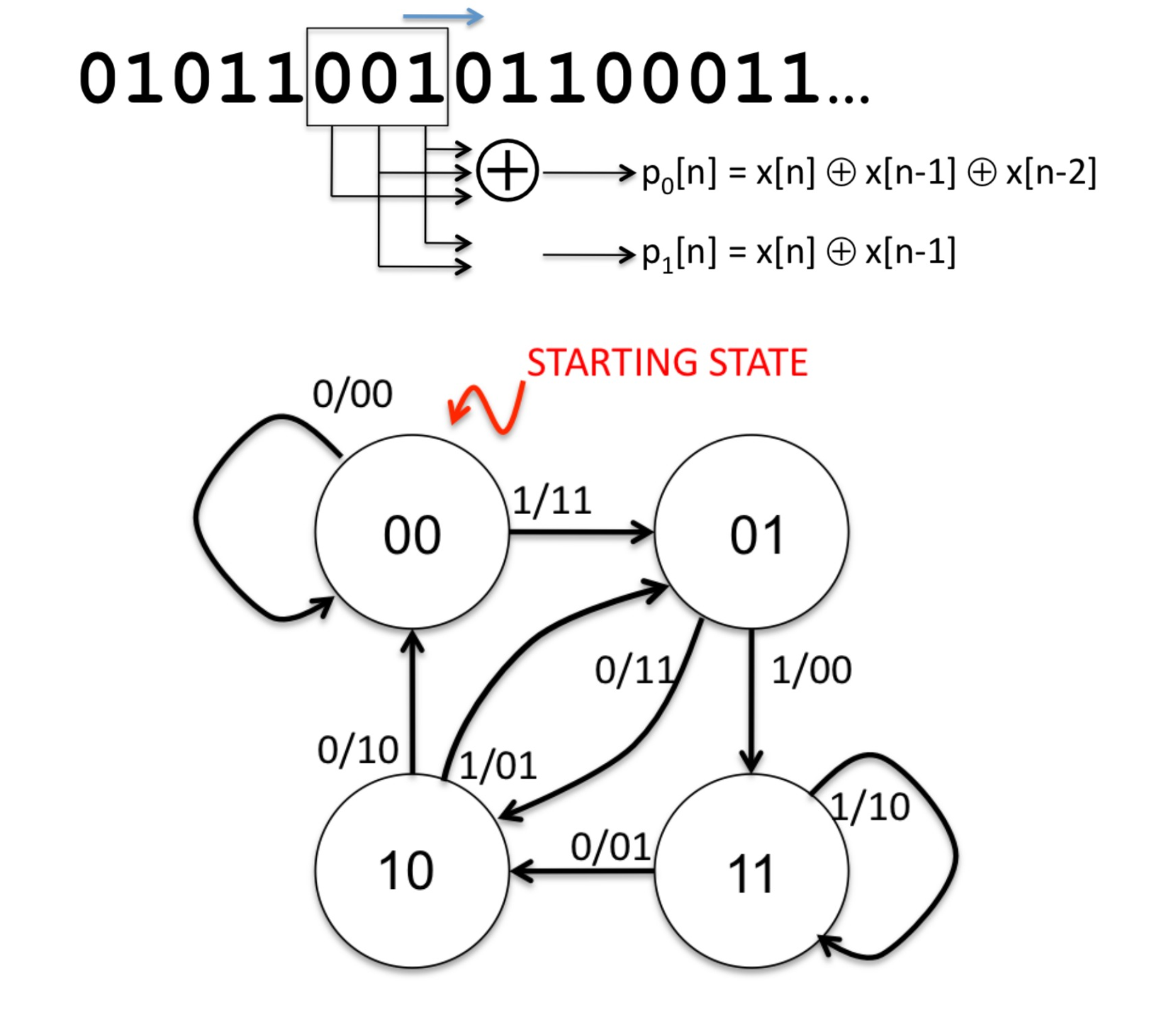
根据输入,我们得到状态转移的路径如下:
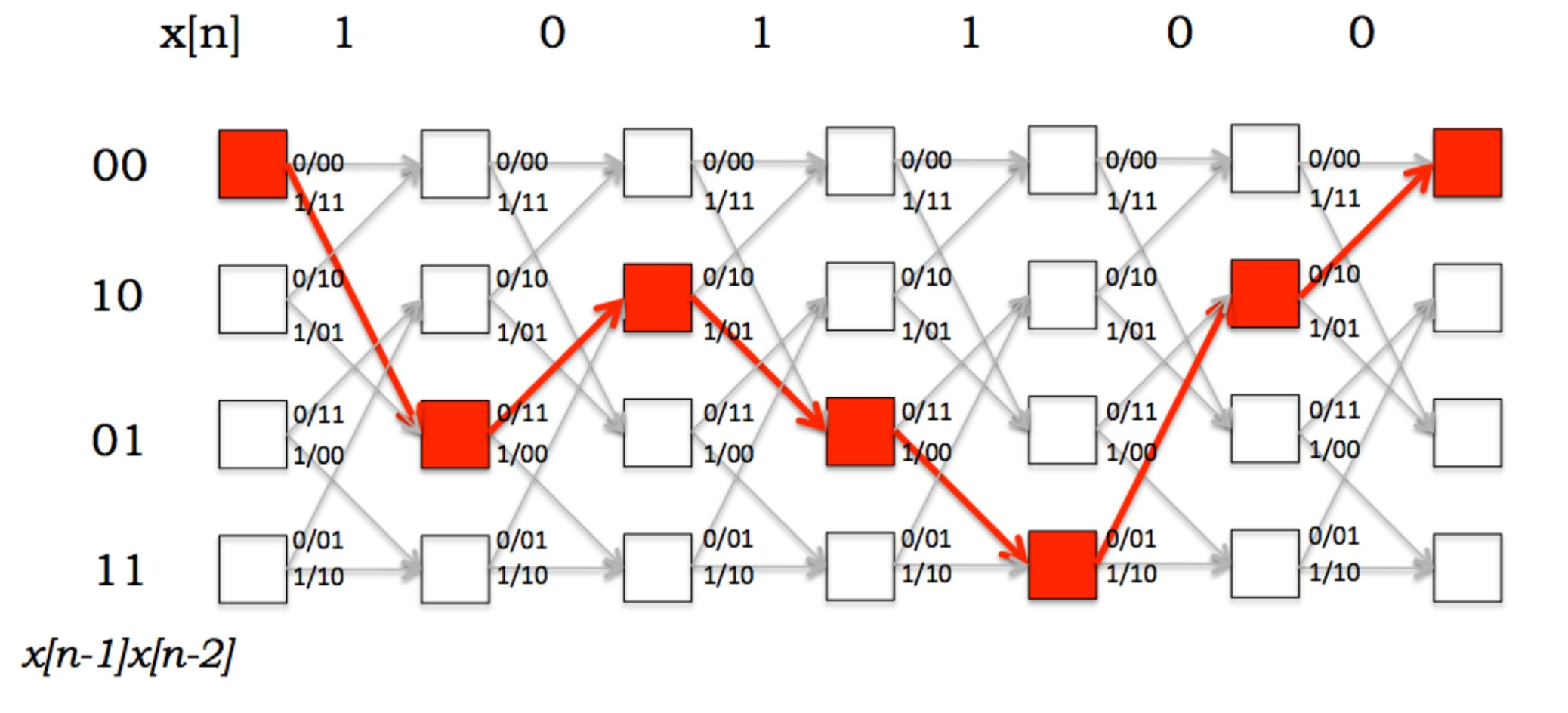
就算接收端收到的数据存在些许差错,也可以根据一定的算法恢复出最有可能的路径。
Detecting Multisymbol Watermark¶
假定在一个 \(L=2,|\mathcal{A}|=1\) 的 2-bit 水印系统中,我们需要判断水印的存在。
Linear Correlative
两个比特位置的水印 \(w_r\) 理想情况下是正交的,对于 D_LC,只要其与 \(w_r\) 的点积绝对值大于一定阈值我们即认为其存在水印,因此共有四种组合情况:
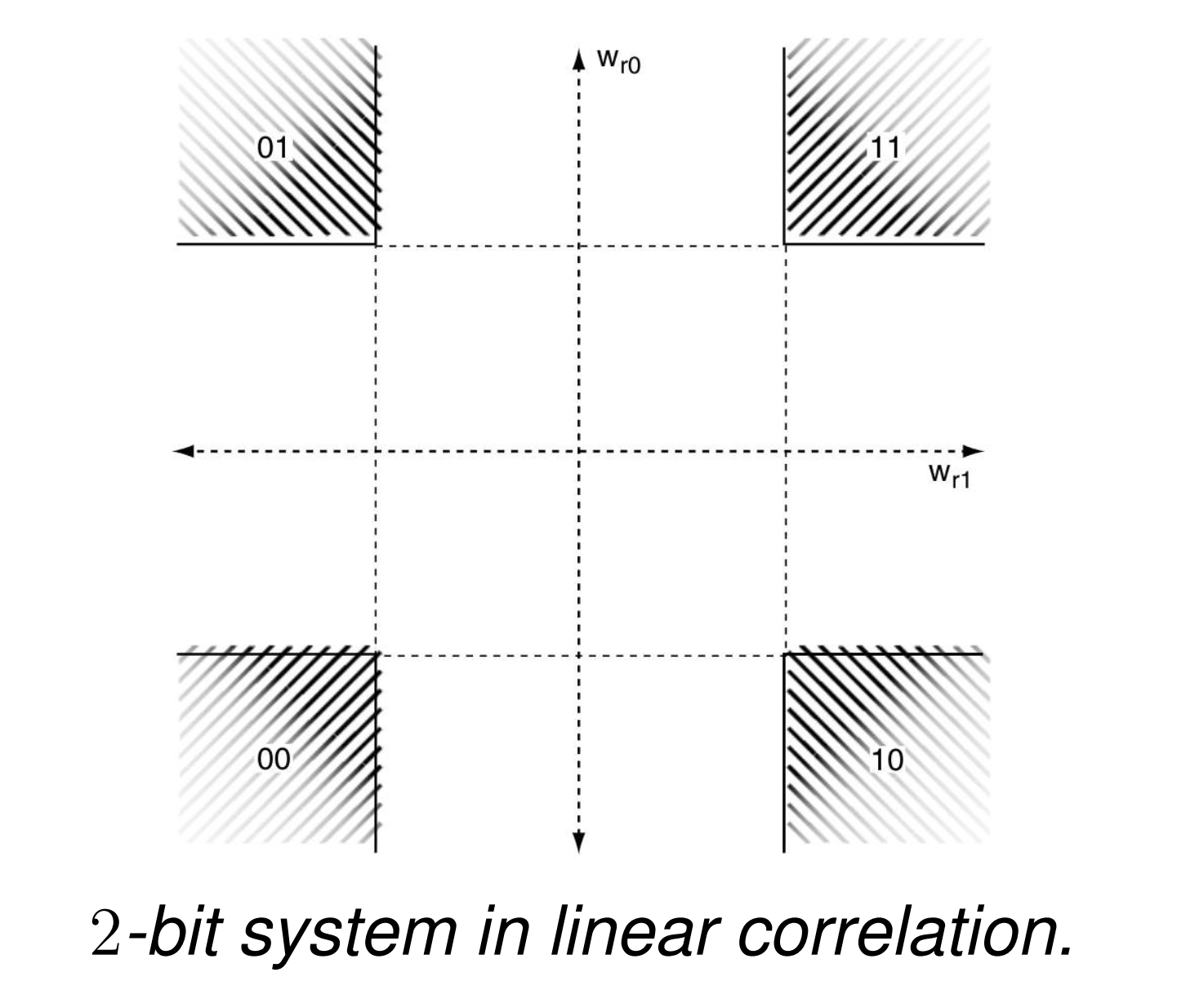
在只有 1-bit 水印的情况下,假设检测的 False Positive Rate(FPR)为 \(P_{fp0}\),那么在 \(L\) sequence, \(\mathcal{A}\) alphabet 的情况下,FPR 为:
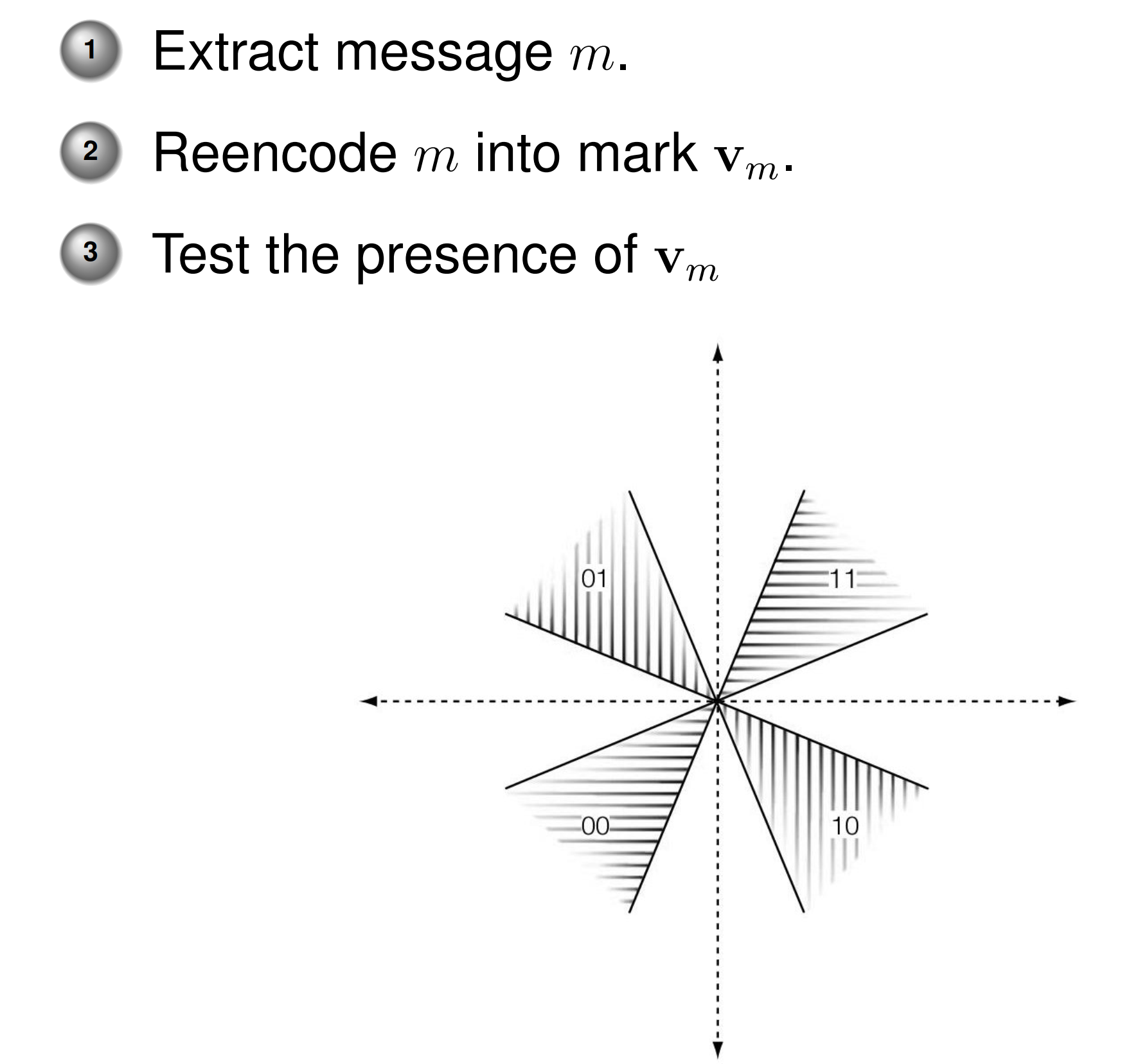
Normalized Correlative
由勾股定理可知,\(||v_{L}||\) 的值约等于 \(\sqrt{L}\):
那么:
\(L\) 的值越大,\(z_{nc}\) 就越接近于 0,相关性就越低。
对于 Normalized Correlative,不同 \(w_{ri}\) 的 Detection Region 之间实际上并没有相交,因此并不能直接像 LC 那样取交集。实际上,我们采用 Reencode,事先编码所有可能的水印情况,接收端收到带水印的作品后进行比对,检测的 FPR 为 \(P_{fp}= |\mathcal{M}| P_{fp0}\):
Side Information¶
Informed Embedding¶
Blind Embedding 在嵌入水印时并不需要 Cover 本体的信息;而 Informed Embedding 则使用了一些附加信息(Side Information)。最简单的例子即为前面讲的 E_FIXED_LC,它对不同的 Cover 计算得到不同的 \(\alpha\)。
在 Embedding 过程中,我们时刻要思考关于置信度和鲁棒性的优化问题:
- <1> 在保持置信度的前提下,最大化鲁棒性
- <2> 在保持鲁棒性的前提下,最小化 Distortion(即获得最好置信度)
- 例如 E_FIXED_LC:\(z_{lc} = \tau _{lc}+\beta\)
不幸的是,更大的 \(z_{nc}\) 并不代表更好的鲁棒性,这点会在之后的一个实验案例中体现。
首先我们仿照 E_FIXED_LC,思考 E_FIXED_CC 的实现可行性:
- 我们知道 NC 以角度来衡量相关性,那么一个合理的思考方式从 \(v_{o}\) 向边界 \(\tau_{nc}\) 做垂线,以此来获得最好的置信度
- 对于二维情况很容易想象,但在更高维时,“垂线”这一概念在几何视角上略显抽象。为此,我们可以换一个坐标系视角来看待,思考在经过 \(v_{o}\) 和 \(w_{r}\) 这两个向量的平面上的计算
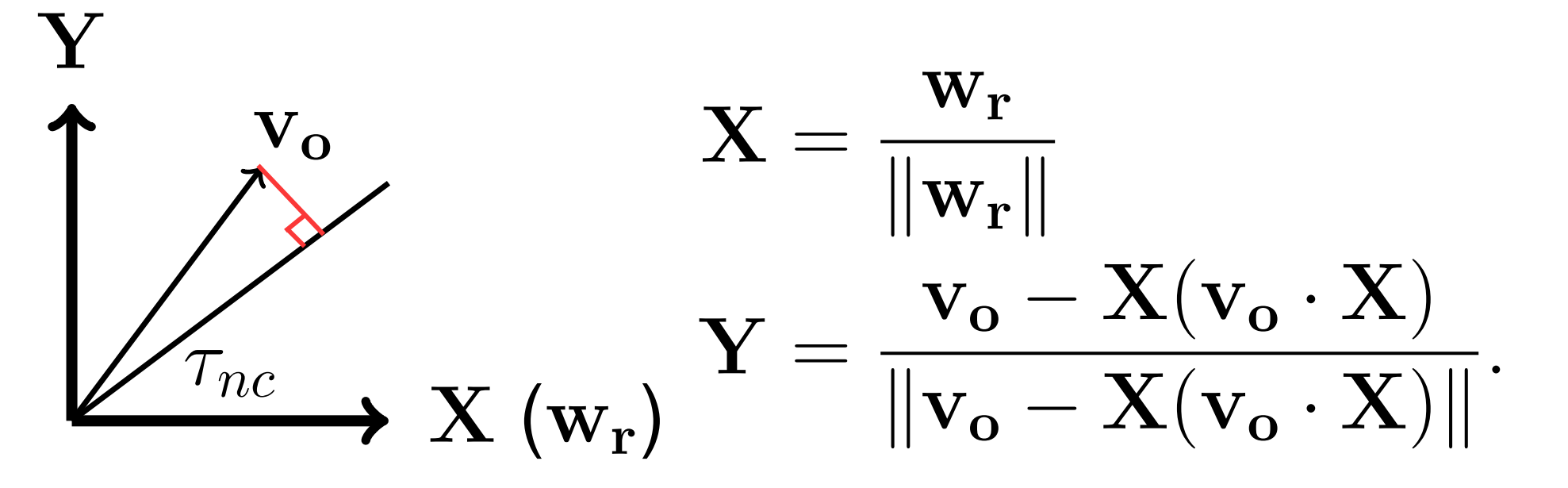
由于 \(w_{r}\) 和 \(v_{o}\) 的平均值都为 0,则 NC 等价于 CC
实际实验中,我们同 E_FIXED_LC 一样,将 \(z_{nc}\) 的值设置为 \(\tau_{nc} +\beta\),根据 \(\beta\) 值的不同,实验结果如下:
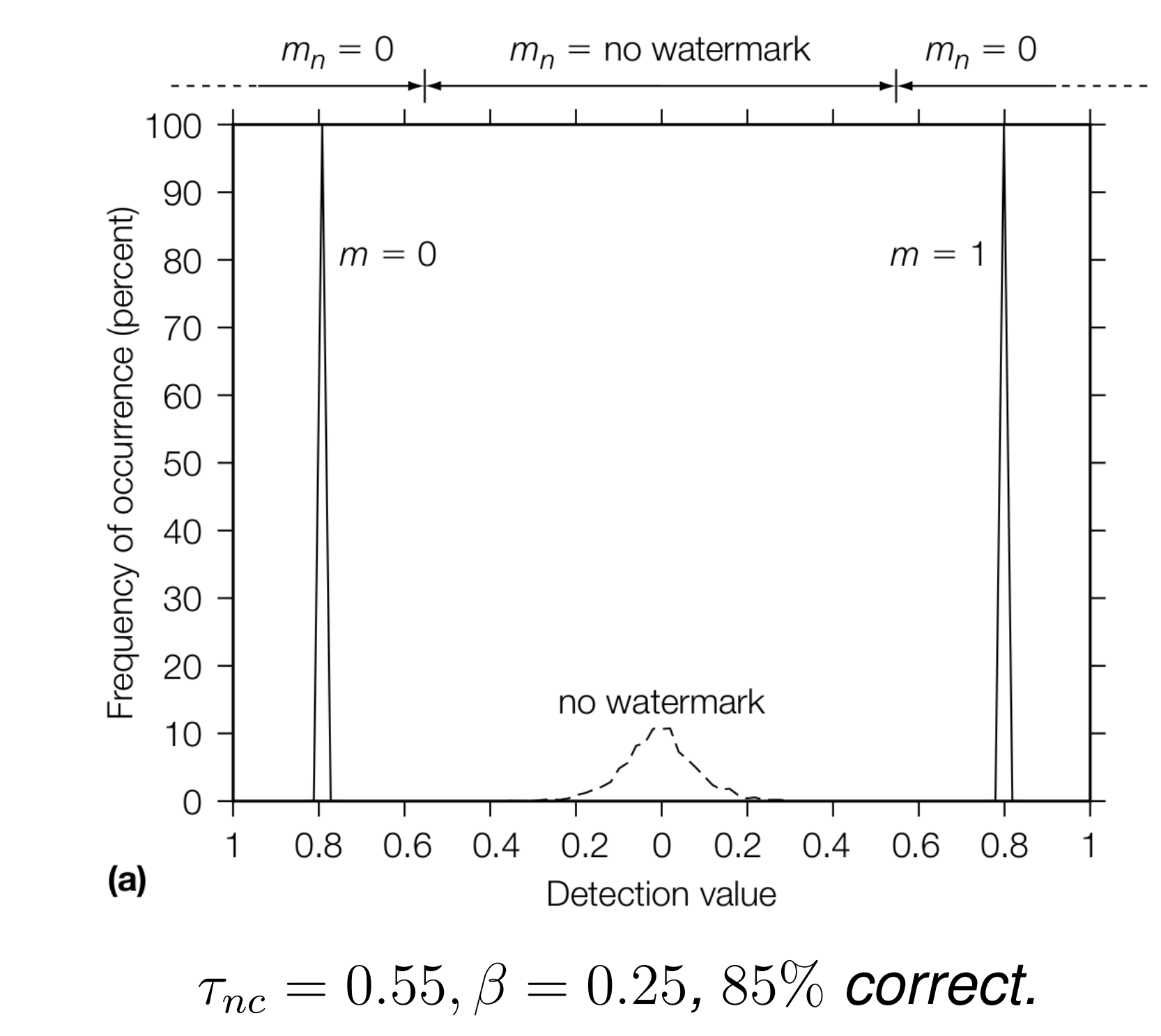
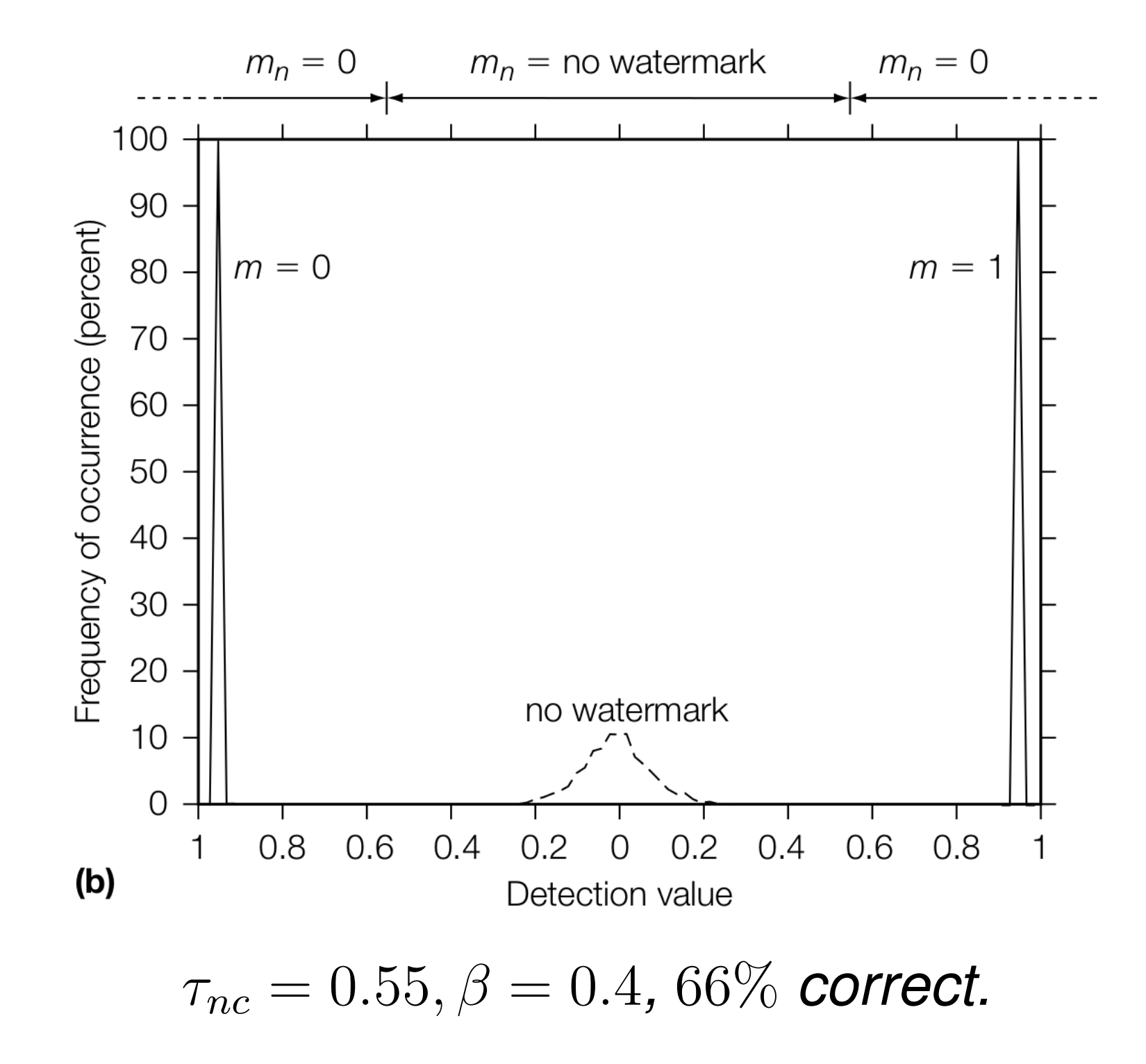
可以看到,随着 \(\beta\) 增大,鲁棒性反而降低。绘制成图像,则可能为如下情况:
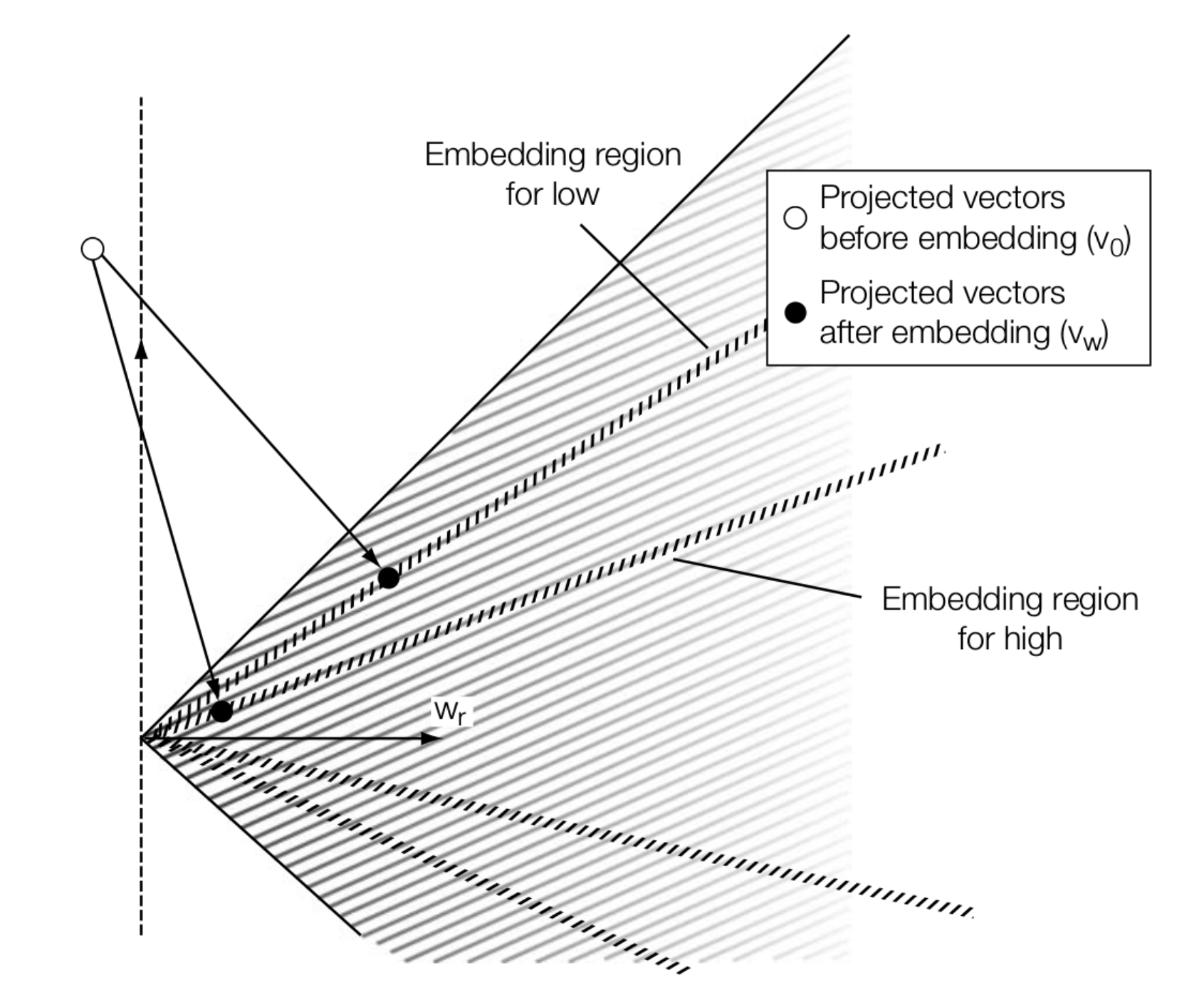
观察到左侧的黑点比右侧的黑点更接近边缘
假设用 \(R^2\) 表示 Detection Region 内某点离开检测域所需的 Distortion,其值计算可约等于:
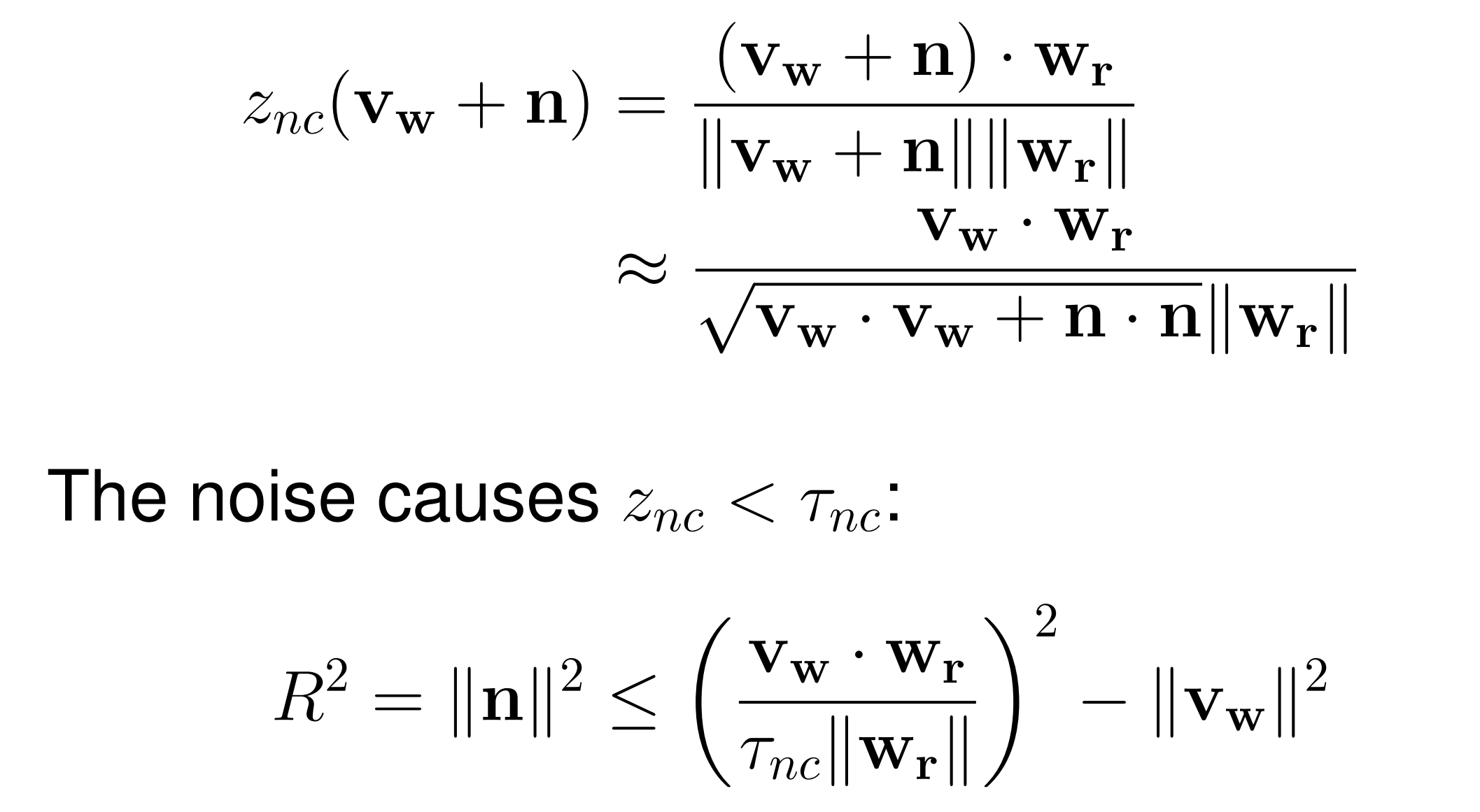
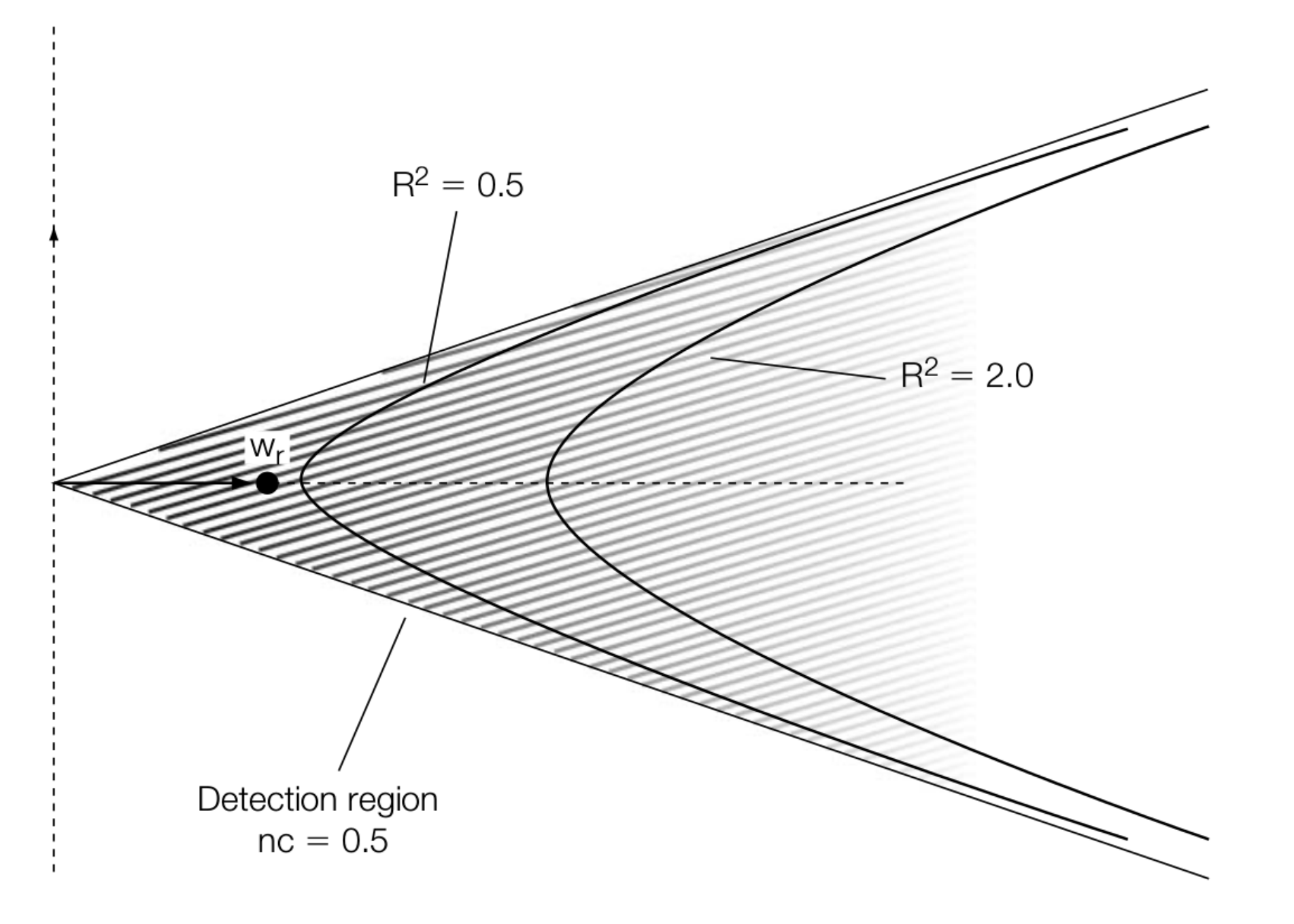
更加优秀的方案选择将 \(v_{o}\) 强行偏移到 \(R^2=xxx\) 的曲线上
Watermarking Using Side Information¶
在 Communication-Based Models 中,假设载体本身存在一定的 State Noise \(S\sim \mathcal N (0,Q)\),再加上信道传输带来的噪音 \(Z\sim \mathcal N (0,N)\),那么该模型的信噪比可以量化为:
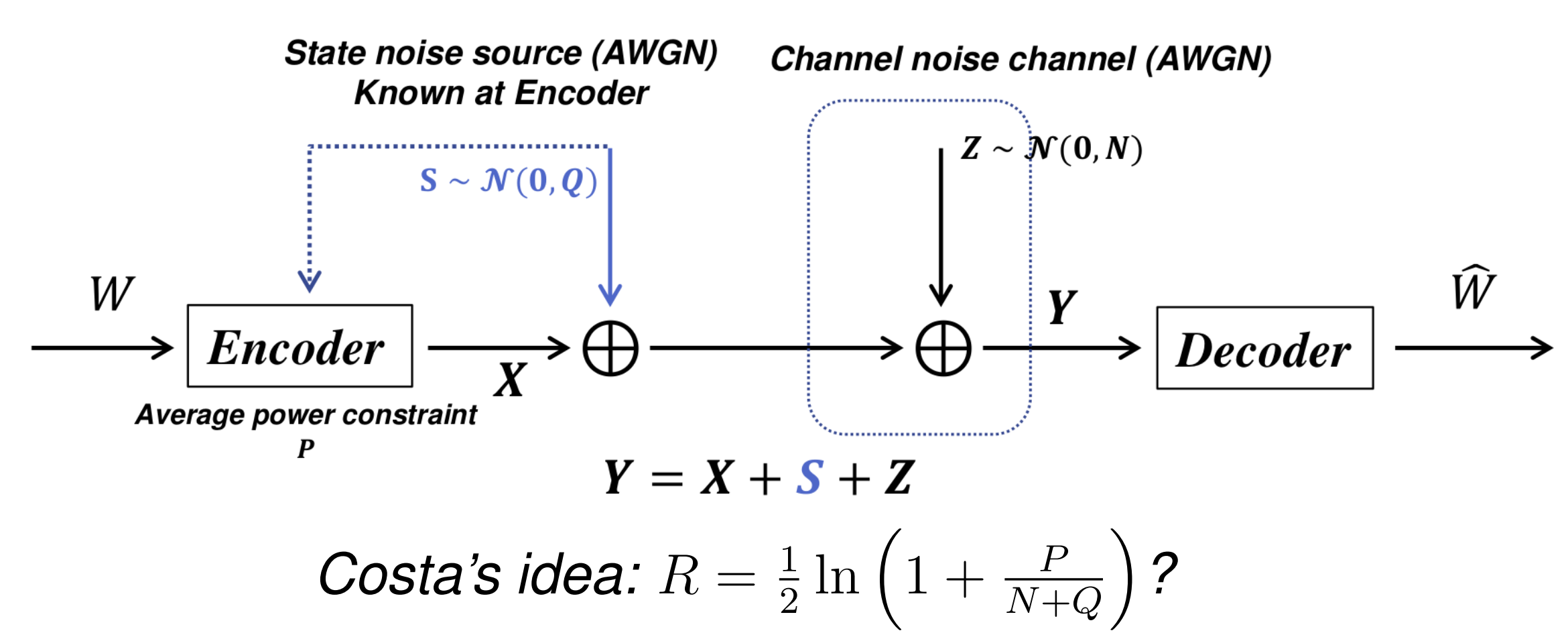
利用 Side Information,我们可以将载体自带的噪音 State Noise 消除,从而将信噪比降为 \(R=\frac{1}{2}\ln \left(1+ \frac{P}{N}\right)\)。
我们将载体看作一张白纸,State Noise 看作纸上的污点。那么,该如何根据这些污点信息来嵌入我们的 Message 呢?

由此,我们提出 Dirty-Paper Code,它与传统的编码不同的是,一个 Message 可能会对应一系列 Candidate Code Words 的集合,嵌入时会从该集合中选出一个最适合该载体的 Code Word 使用。
依旧考虑 1-bit 的信息,显而易见的是该系统的 False Positive Rate 的值与码字集合的大小线性相关,即: