Steganography¶
约 4008 个字 预计阅读时间 20 分钟
Introduction¶
- 水印(Watermark) 追求的目标是不可感知(Imperceptible)——嵌入的信息人眼/耳看不见,但允许存在统计上可检测到的痕迹。版权保护场景下,即使对手知道"这张图可能含水印",他们也需要特定密钥才能读出水印内容。
- 隐写术(Steganography) 追求更高的目标——不可探测(Undetectable)。不仅内容不可读,连"是否存在隐藏信息"这件事本身都不能被察觉。换句话说,含密图像(stego image)和普通图像的统计分布必须无法区分。
这个区别决定了两者在设计时的根本权衡:水印可以为了鲁棒性牺牲一些统计隐蔽性,隐写术则必须将统计不可区分性置于首位。
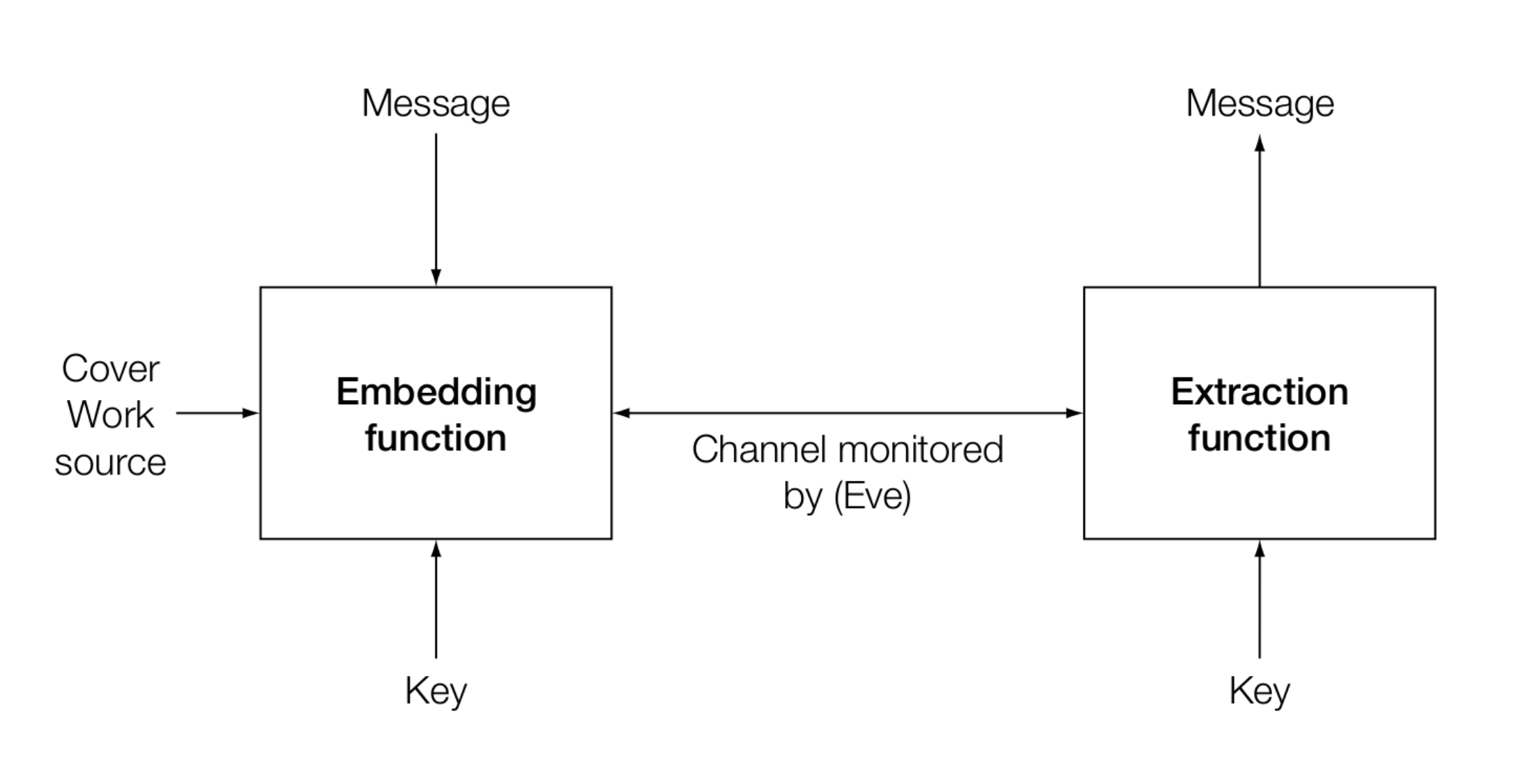
在通信模型中,发送方和接收方持有相同密钥,而在信道中传输的 Stego Work 则可能被监控信道的 Wardon(守卫)监听到。根据 Wardon 对信道的干预程度,我们分为:
- 被动守卫(Passive Warden) — 被动守卫只观察、分析,不修改传输内容。他的目标是判断"是否有秘密通信在发生",但不会破坏内容。这是隐写分析(steganalysis)的典型场景。
- 主动守卫(Active Warden) — 会对传输内容进行修改(如压缩、加噪),以破坏可能存在的隐藏信息。此时嵌入算法需要具备一定的鲁棒性。
- 恶意守卫(Malicious Warden) — 最具威胁性,不仅分析和修改内容,还可能主动冒充 Alice 或 Bob,进行中间人攻击。
本课程大部分内容集中在 Passive 的模式,即只对 Stego Work 进行隐写分析
根据载体作品的来源与处理方式,嵌入分为三类:
- 1. 覆盖查找(Cover Lookup) 载体作品预先存在且不被修改。发送方从一个大型数据库中选择最适合携带目标消息的载体来传输。载体本身不变,消息通过"选择哪个载体"来编码。
- 2. 覆盖合成(Cover Synthesis) 载体作品是按需生成的,同样不会被修改。生成过程本身受消息控制,输出的是一个自然的合成载体。
- 3. 覆盖修改(Cover Modification) 最常见的方式:使用一个预先存在的载体,通过对其进行细微修改来嵌入消息。绝大多数实际隐写系统(包括 LSB、OutGuess、F5 等)都属于这一类。
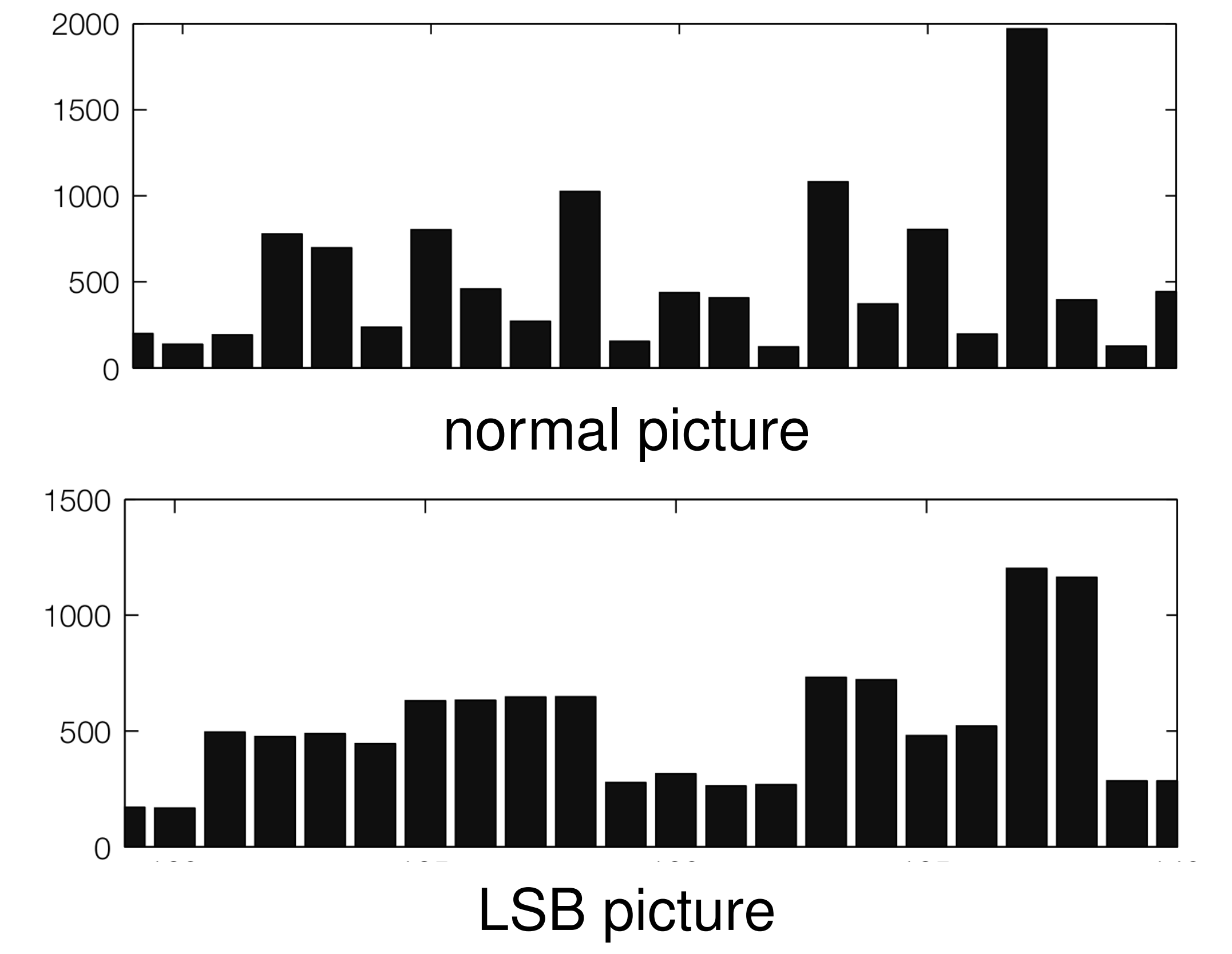
作为隐写术的简单尝试,我们使用 LSB 进行消息嵌入。我们将像素分为不相交的对 \((2i,2i+1)\),人眼无法简单差距一个对之间像素值的差异。嵌入时:
- 要嵌入比特 1:将像素值设为偶数→奇数,即 2i → 2i+1
- 要嵌入比特 0:将像素值设为奇数→偶数,即 2i+1 → 2i
这样每个像素可携带 1 bit,且修改幅度仅为 ±1。然而,虽然 LSB 单次修改幅度小,但大量替换后,图像的像素值直方图会产生明显的“配对效应”,一个对的两个值会趋向均等,这种统计异常极易被检测:
OutGuess¶
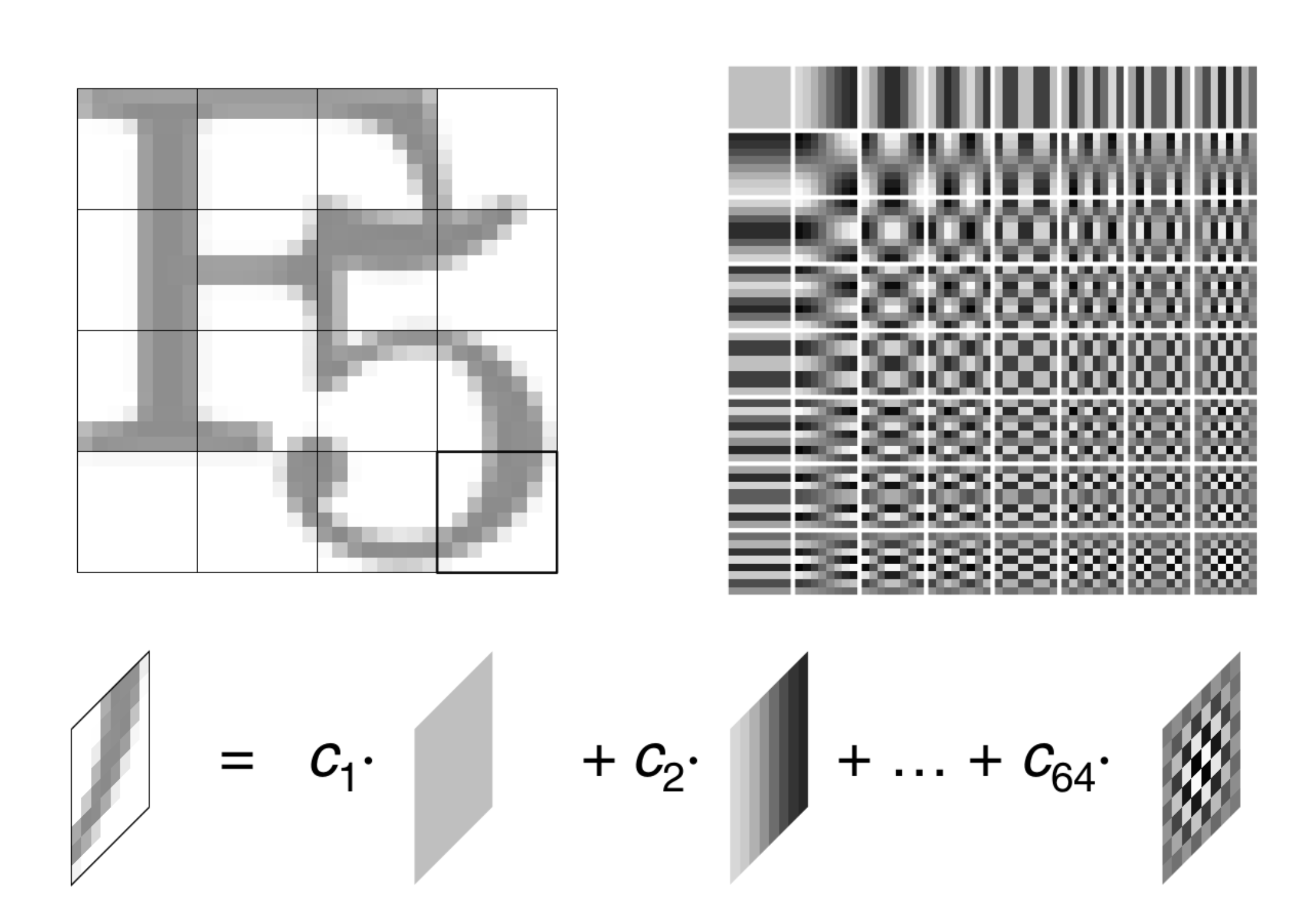
JPEG 将图像分割为 8×8 像素块,对每块做 DCT,得到 64 个 DCT 系数 \(c_{1}, c_{2}, \cdots, c_{64}\),其中:
- \(c_1\) 是 DC 系数(直流分量,代表块的平均亮度)
- 其余是 AC 系数(交流分量,代表不同频率的细节)
量化步骤:将 DCT 系数除以量化步长并取整,高频系数(人眼不敏感)被大幅量化为 0,实现压缩。
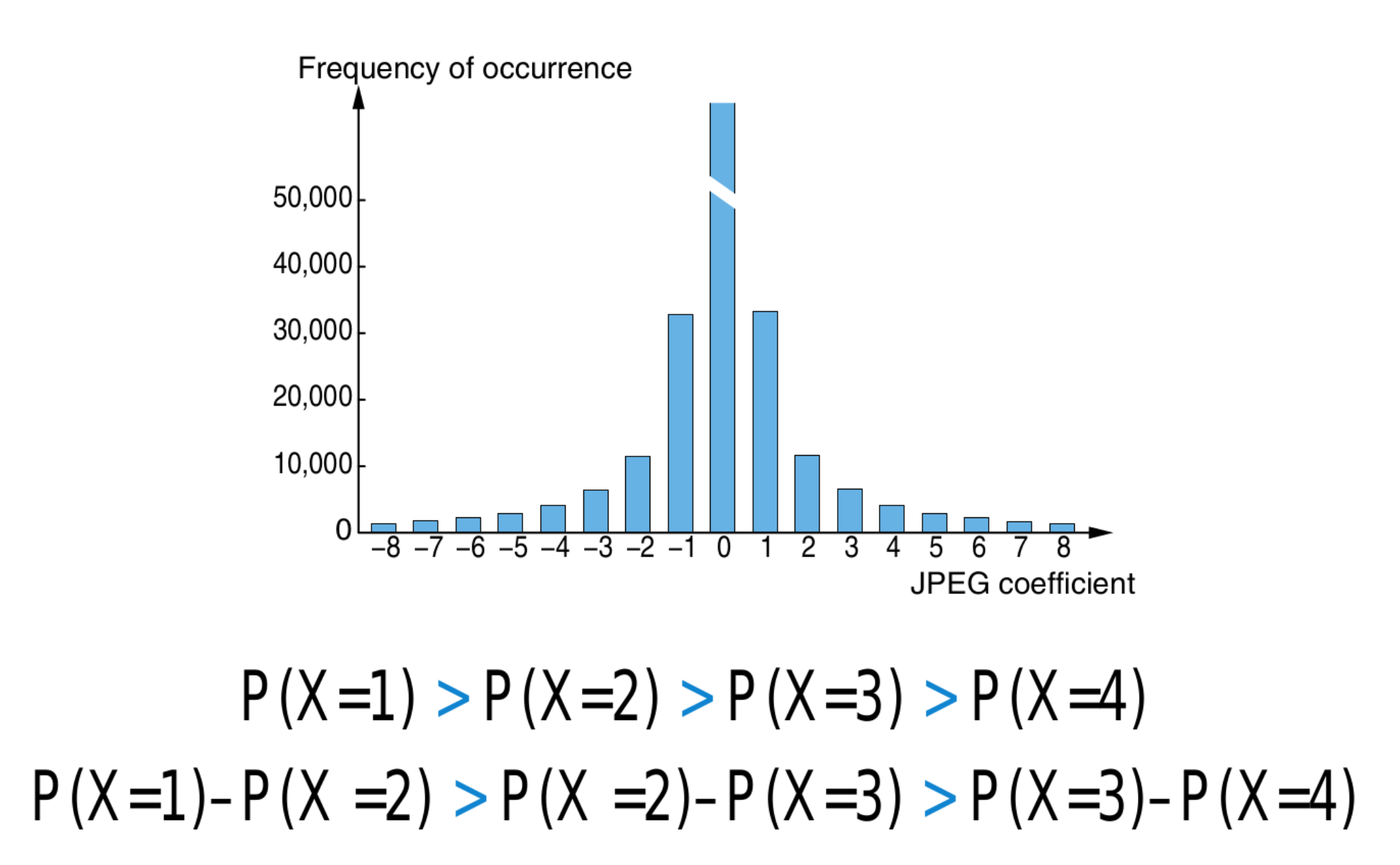
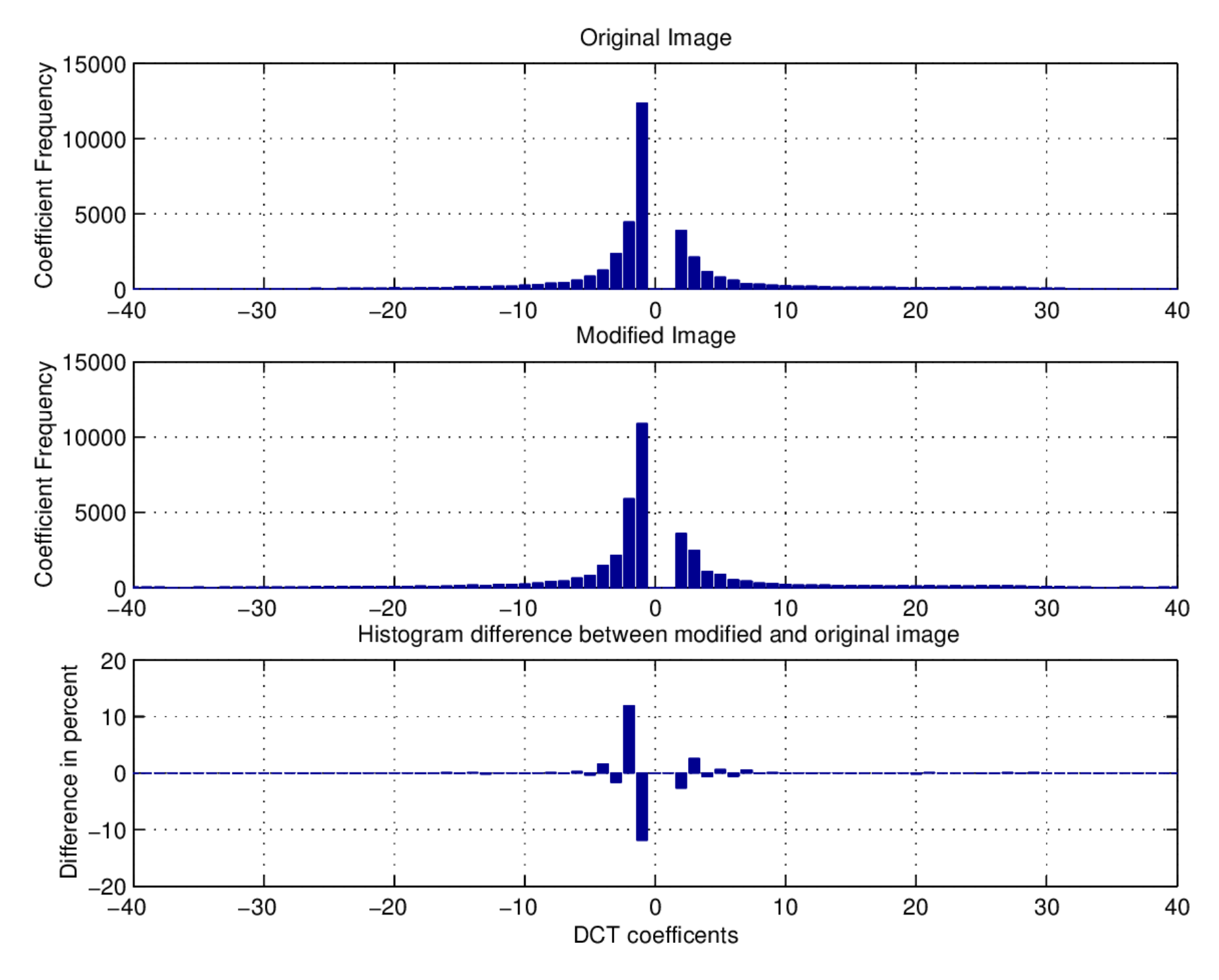
在统计上,对于 JPEG 图像的 DCT 系数直方图,系数等于 0 的频率有巨大的峰值,并且向两边递减下降,相邻柱形的频率差也单调递减:
OutGuess 是一个专门针对 JPEG 图像的隐写算法,目标是在嵌入消息的同时保持 DCT 系数的统计特性,它在嵌入后会再进行一次修正:
- 第一遍(嵌入):沿伪随机游走路径,用 LSB 替换方法将消息嵌入选定的 DCT 系数。此时直方图已被破坏。
- 第二遍(修正):遍历未被第一遍使用的系数,通过选择性地翻转这些系数的值,将直方图修复到接近原始状态。
- 嵌入容量的上限:OutGuess 的最大嵌入量不能无限增加,受限于"最不平衡的 LSB 对"。
对于一个值对 \((U, L)\)(其中 \(U\gt L\) 是正常状态),设用于嵌入的比例为 \(q\in [0,1]\):
- 嵌入后 \(U\) 减少为 \(U-(U−L)\cdot q/2\)
- 嵌入比例为 \(q\),而每次嵌入有 \(1/2\) 概率修改 LSB,考虑到 \(U\rightarrow L\) 和 \(L\rightarrow U\)
- 修正时最多能将 \(L\cdot (1−q)\) 个系数改回 \(U\)
- 因为 \(L\cdot q\) 部分都在第一遍被嵌入(就算它没有被修改)
为了抵消 \((U-L) \cdot q/2\) 的影响,将 \(U/L\) 恢复到初始比例,我们需要保证:
因此,越不平衡的对(\(L\) 很小),能承载的嵌入比例 \(q\) 就越低,从而限制了总嵌入容量。
通常我们不对 \((0,1)\) 这一对 DCT 系数进行修改,因为这会显著影响直方图
Model-Based Steganography¶
广义柯西分布 GCD 对 DCT 系数分布进行了精确数学建模:
该分布函数的两个可调整参数为 \(p\gt 1, s\gt 0\)。对于隐写术,如果嵌入后的含密图像其系数分布仍然完美符合 GCD,则守卫从统计角度无法区分。因此,嵌入过程需要将消息 bit 映射为符合 GCD 的系数修改模式。
嵌入的消息比特流可能是均匀分布(uniformly distributed)的,我们可以通过算术编码 Arithmetic Coding 将其转换为更符合 GCD 分布的系数修改序列:
- 嵌入时(解压缩方向): 均匀分布比特流 → 算术解压 → GCD 分布比特流 → 用来修改 DCT 系数
- 提取时(压缩方向): 从 DCT 系数读出 GCD 分布比特流 → 算术压缩 → 均匀分布比特流(即原始消息)
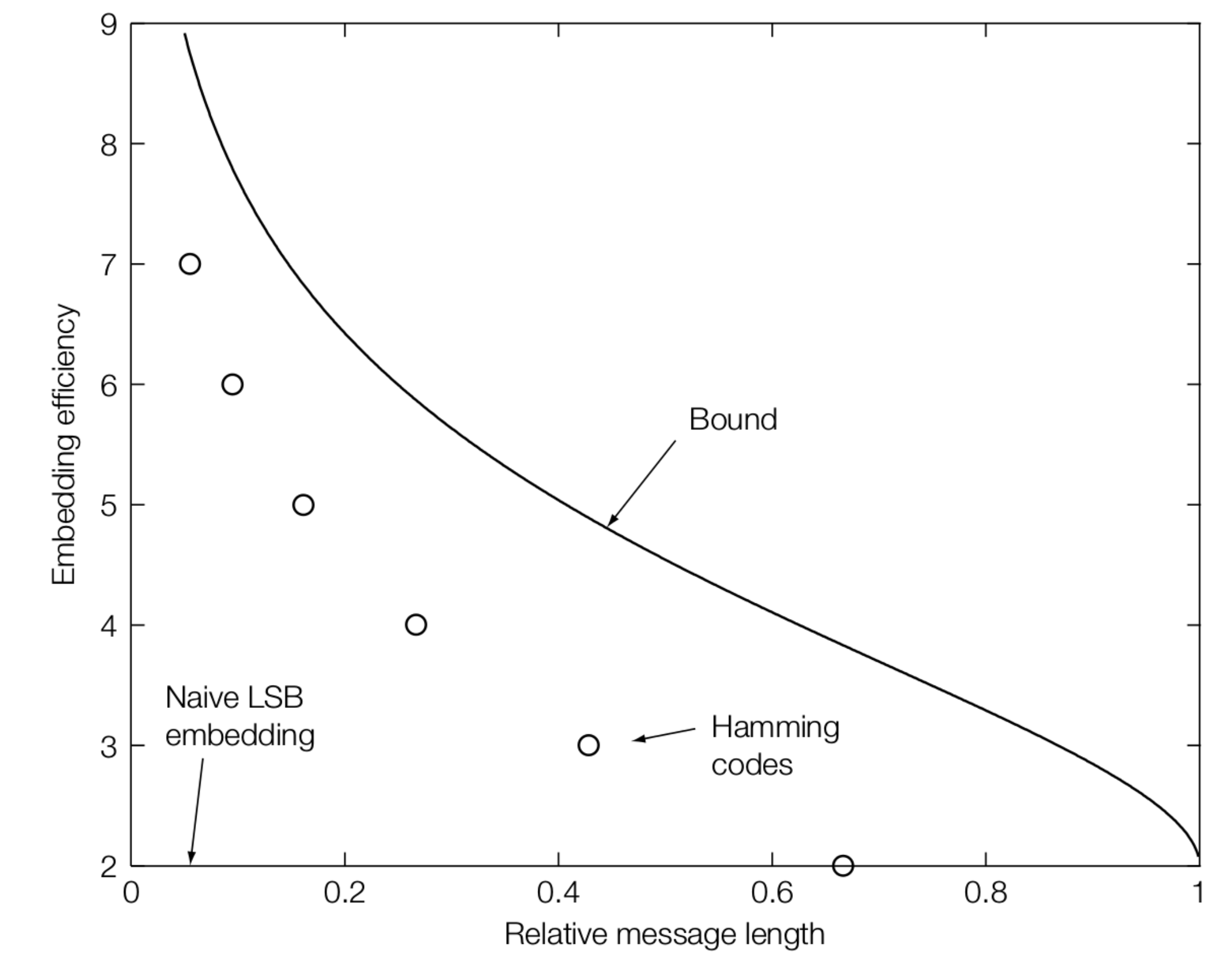
我们定义嵌入效率 Embedding Efficiency 为每单位修改所能嵌入的平均比特数,这是衡量隐写算法优劣的核心指标之一。
以 LSB 的嵌入效率为例
- 每像素嵌入 1 bit
- 修改概率为 0.5
- 效率 \(=1/0.5=2\)
对于值对 \((2i,2i+1)\),\(2i\) 的概率为 \(p_0\),基于信息论,可以得到基于模型的隐写术方法的嵌入效率计算公式为:
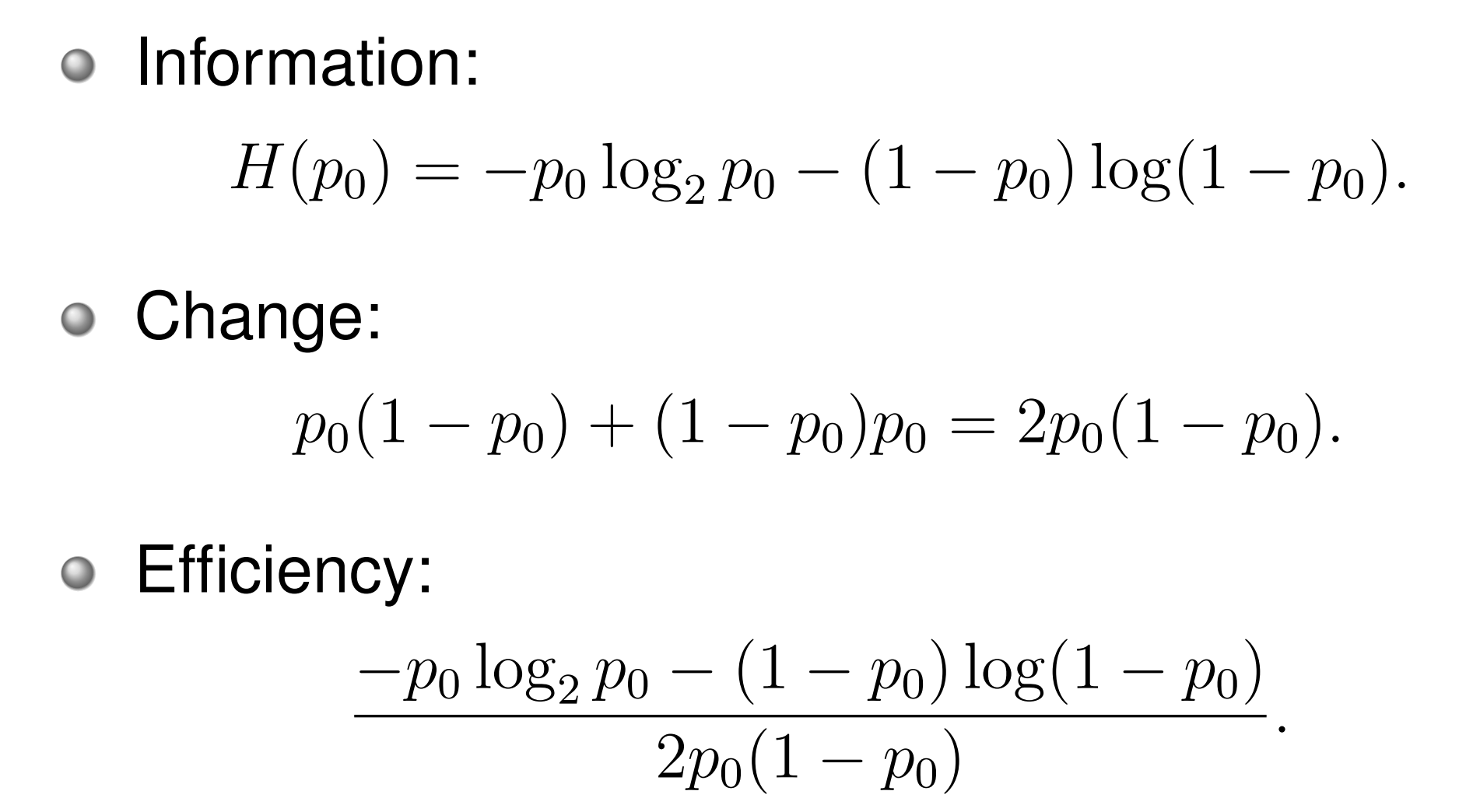
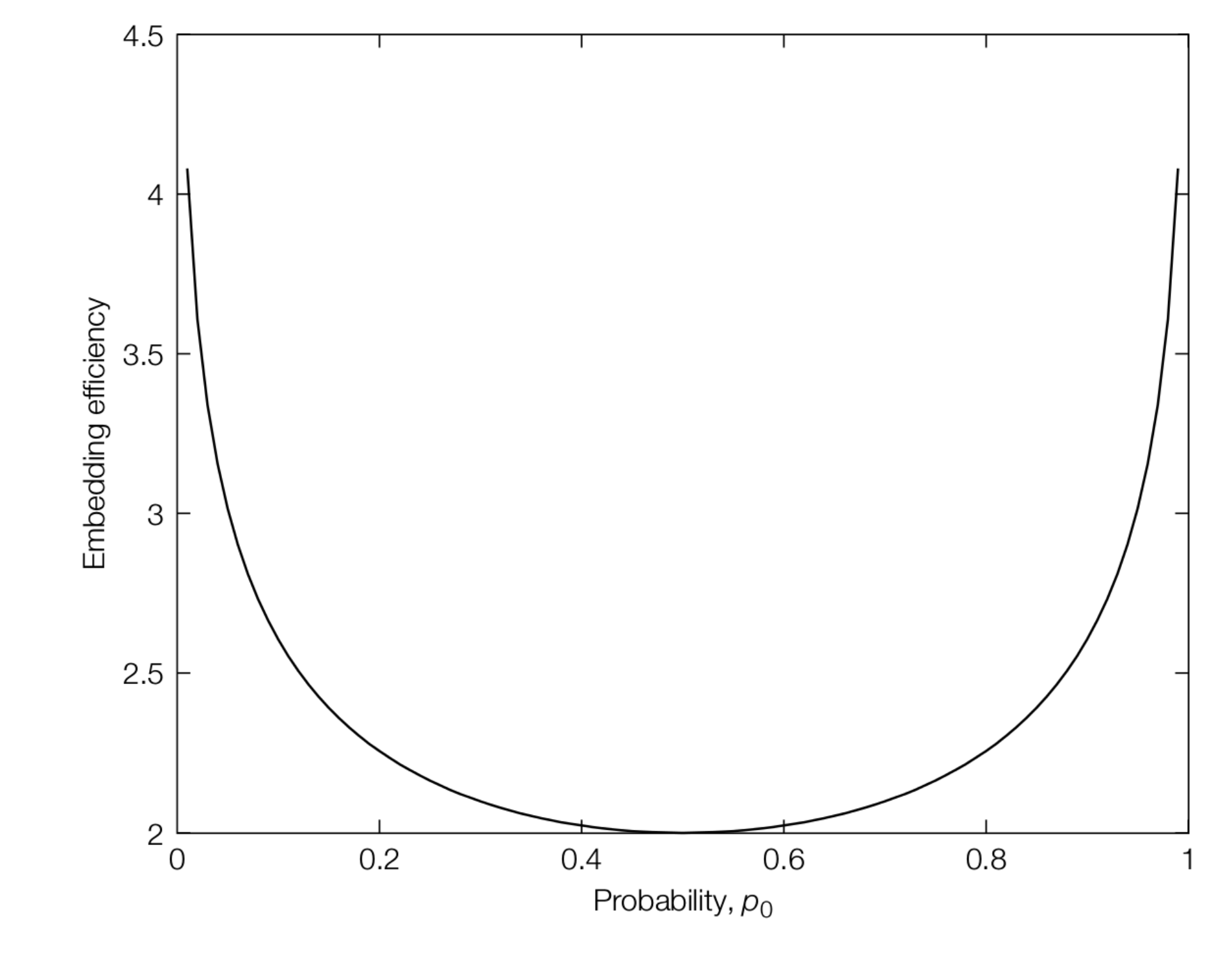
将嵌入效率和 \(p_0\) 绘制成函数图,则可见当 \(p_0=0.5\) 时嵌入效率最低(退化到 LSB);系数分布越不平衡,嵌入效率越高:
Masking Embedding as Natural Processing¶
本节介绍的算法的核心思想均为“让隐写看起来像正常压缩流程”,其具体有两条实现路线:
- 保留统计特性——修改方式要让DCT系数的直方图分布保持和未处理图像一样,代价是损失一部分嵌入容量(capacity)。
- 模仿自然过程——让修改行为和JPEG正常量化取整的过程高度相似,使攻击者无法区分"嵌入过"还是"正常压缩过"。F3、F4、F5就是这条路线下逐步演进的算法家族。
Jsteg¶
Jsteg 是 JPEG 域最早、最朴素的隐写方案,其相当于 DCT 系数域的 LSB 替换。
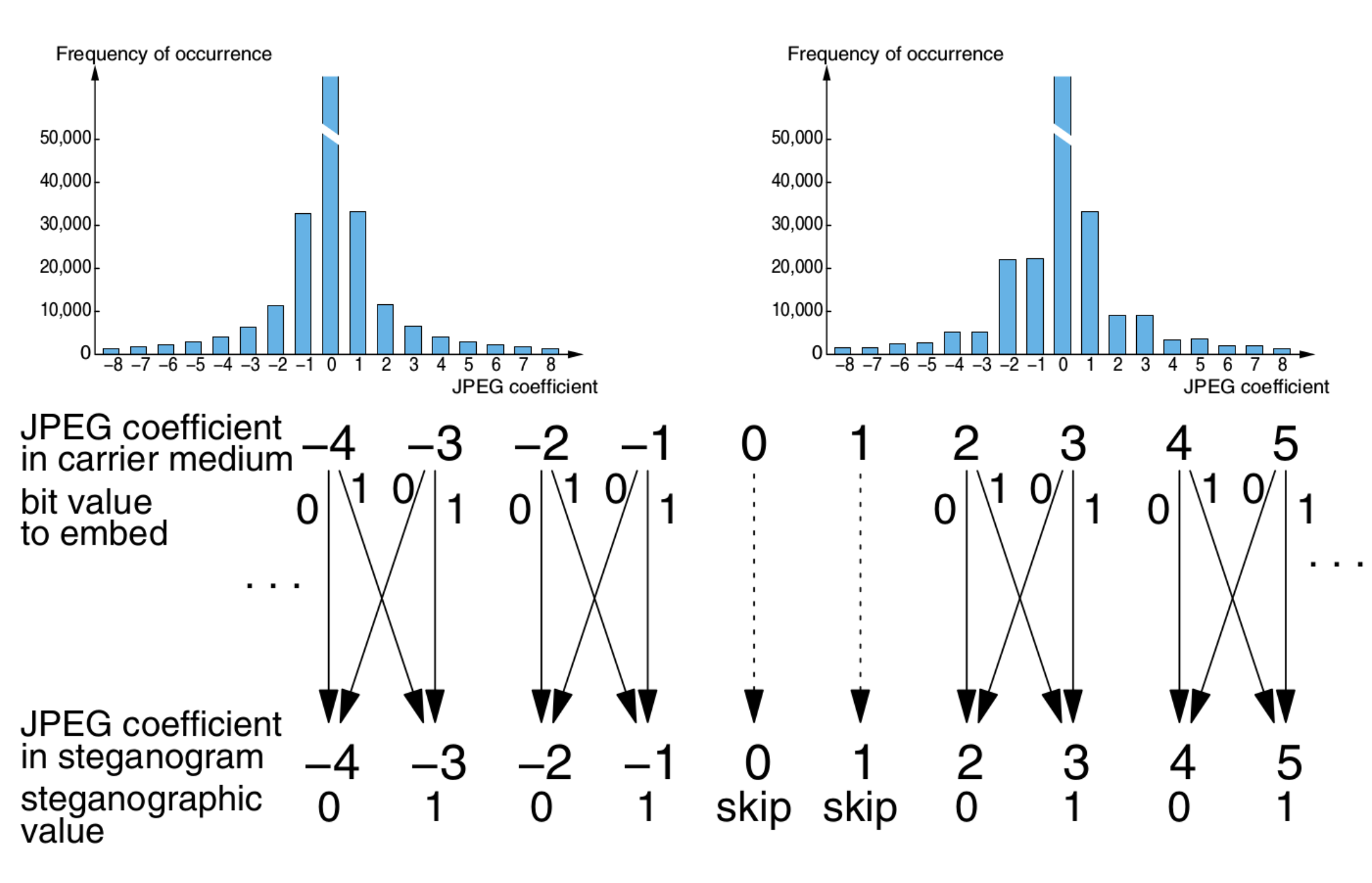
同 LSB 隐写一样,Jsteg 会导致 DCT 系数直方图的 \((2i,2i+1)\) 对趋于相同,这个异常可以轻易被统计检验发现。
F3¶
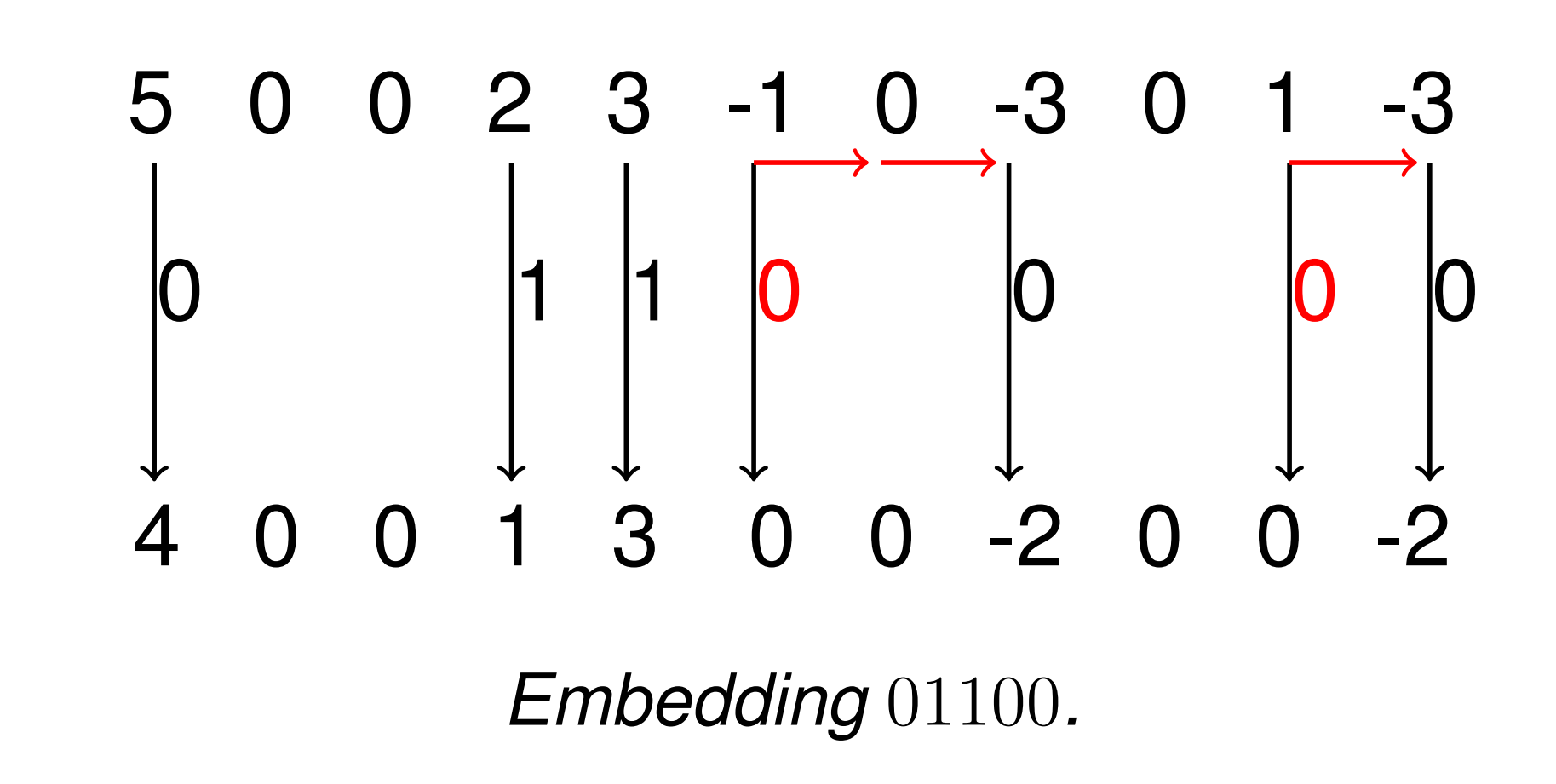
F3的改进思路:调整系数时向0方向收缩,而不是直接替换LSB。除此之外,若调整后系数变为 0,则跳过这个系数,继续用下一个系数嵌同一个消息位,这被称为 Shrinkage。
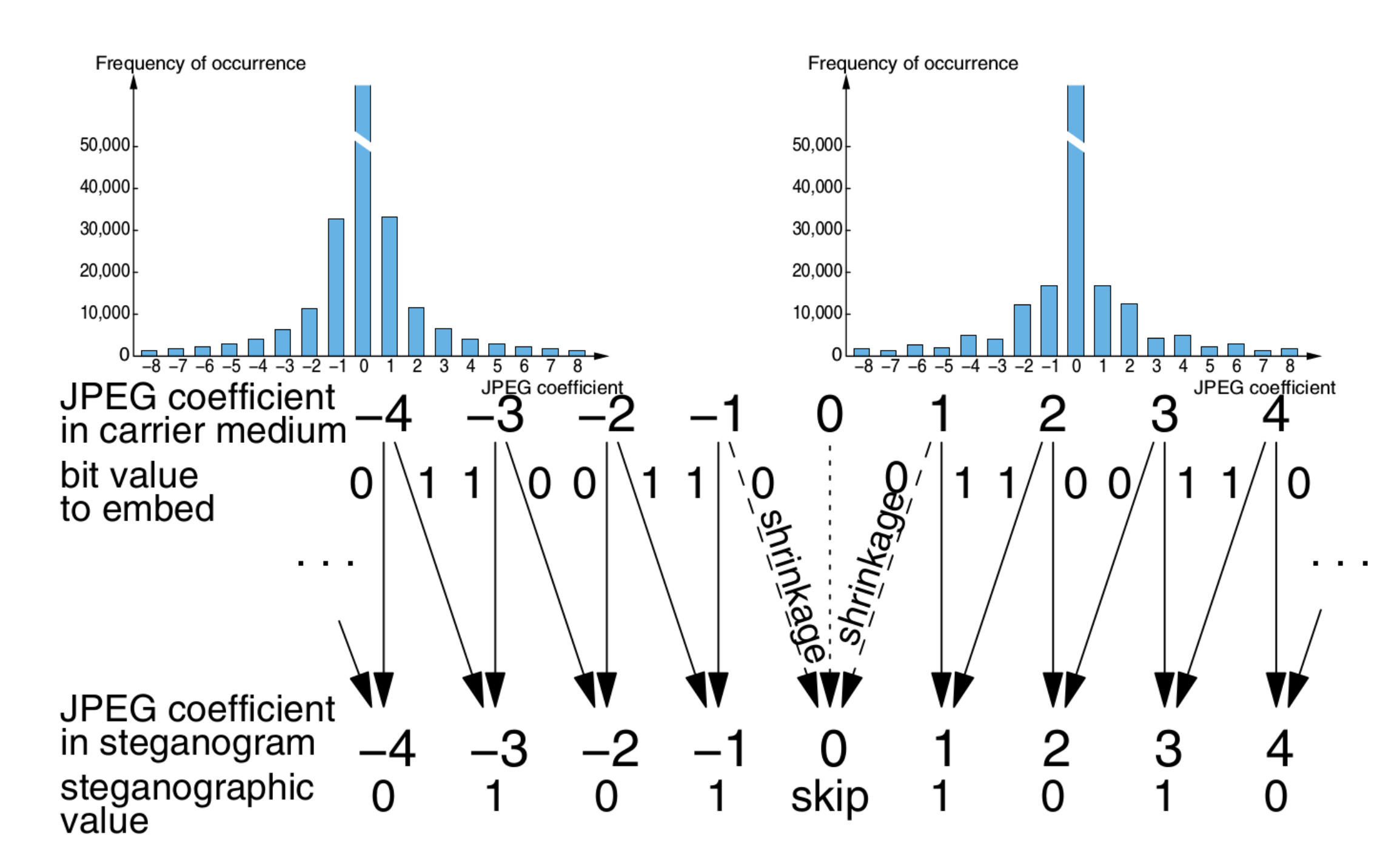
Example
F3 只在嵌入 0 时发生收缩,这等效于消息位嵌入了更多的 0,导致嵌入后的 DCT 系数可能发生 \(P(2i)>P(2i-1)\)。这既破坏了统计,又浪费了容量。
F4¶
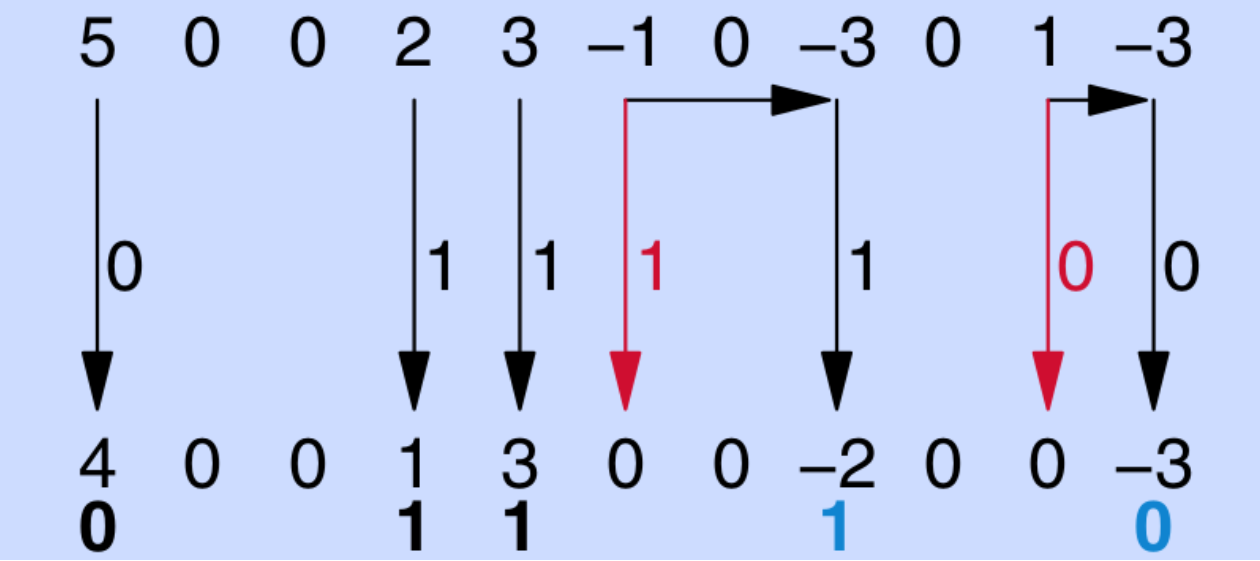
F4的核心改进:对负系数反转嵌入,使得收缩在嵌 0 和嵌 1 时概率相等,从而修复直方图异常。
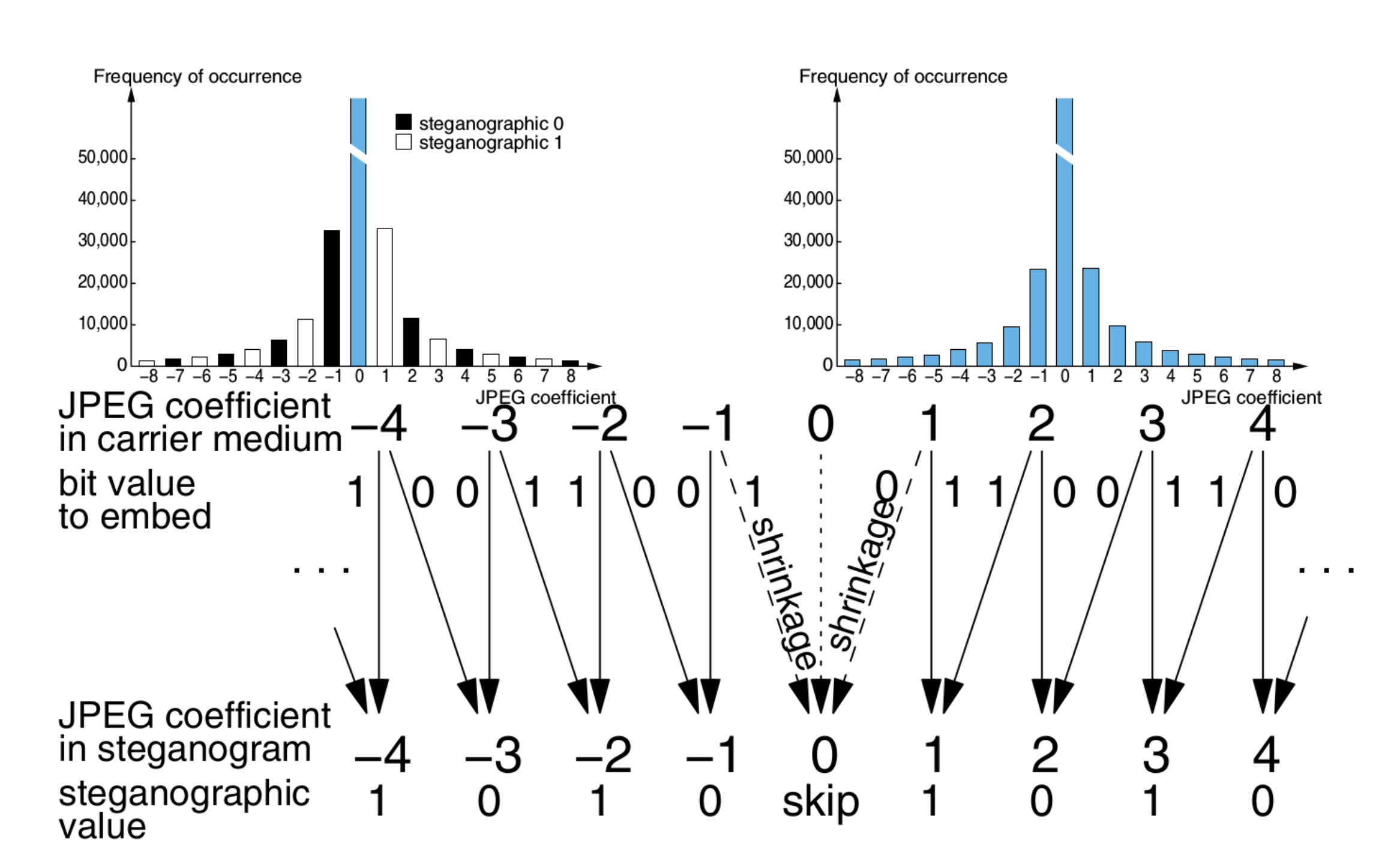
Example
值得一提的是,上述几个算法都是直接遍历系数进行嵌入,导致图像被修改部分集中在上部。攻击者可以通过比较 JPEG 图像的相似块,或者用逆向 GCD 分析来推断出哪些系数被修改过。
解决方案是采用随机游走 Random Walk,用密钥生成伪随机遍历顺序,打乱嵌入位置。

F5¶
F5 算法通过矩阵编码大幅提升嵌入效率,相当于 F4 + Matirx Encoding + Random Walk。
以最简单的 \((3,2)\) 矩阵编码为例,如果我想要嵌入 2 bit 消息 \(b_{1}, b_{2}\) 到 \(x_{1}, x_{2}, x_{3}\) 中,那么我们比对:
如果消息不满足以上关系,我们只需要修改一个系数即可:
| 哪个等式不满足 | 00 | 10 | 01 | 11 |
|---|---|---|---|---|
| 修改哪个系数 | / | \(\bar{x_1}\) | \(\bar{x_3}\) | \(\bar{x_2}\) |
Embedding Efficiency
推广到一般情况,对于 \(p\) 位消息,我们使用 \(2^p-1\) 个系数用于嵌入,则对应的矩阵编码为 \(H\in \{0,1\}^{p×(2^p−1)}\) 。如果我们收到了嵌入后的序列 \(c\),那么可以直接通过 \(m=Hc\) 来提取出 \(p\) 位消息。
由于每次嵌入只用修改 1 bit,我们的平均修改次数为 \(0\times \frac{1}{2^{p}}+ 1 \times ( 1 - \frac{1}{2^{p}})\),那么嵌入效率为:
| p | 系数 2ᵖ−1 | 效率 p/(1−1/2ᵖ) |
|---|---|---|
| 1 | 1 | 2 |
| 2 | 3 | 8/3 ≈ 2.67 |
| 3 | 7 | 24/7 ≈ 3.43 |
| 4 | 15 | ≈ 4.27 |
| ∞ | ∞ | → ∞ |
由此可见 \(p\) 越大效率越高,但同时每次嵌入需要更多系数,容量(payload)下降。
Embedding Efficiency 存在上界,具体推导可见课件
Selection Rule¶
像 Random Walk 这种,收发双方通过相同密钥就能知道哪些位置被使用的选择规则称为 Shared Selection Rule。
Nonshared Selection Rule 则是只有发送方知道哪些位置被嵌入,而接收方需要额外的约定才能获取这些位置,然后恢复消息。
例如,我们可以利用 JPEG 量化时的取整进行嵌入。我们知道,JPEG 计算的 DCT 系数是浮点数,发送方可以计算得到量化前的系数浮点值。接下来选取舍入误差最大的系数进行优先嵌入。例如,我们要嵌入浮点值 \(5.47\):
- 若要嵌 0(目标整数值为偶数6):距离 +0.53
- 若要嵌 1(目标整数值为奇数5):距离 −0.47
为什么选舍入误差最大(最接近 \(x.5\))的系数?
嵌入这些系数更接近正常量化误差,使得统计特性更自然
Wet Paper¶
湿纸码是一个信息论问题,用"在湿纸上写字"作为比喻:
- 载体图像 x:有"湿区域"(不可修改)和"干区域"(可修改)
- 发送方:知道湿区域在哪里,只能修改干区域
- 接收方:收到图像时纸已干,不知道哪些位置原来是湿的
- 问题:如何在接收方不知道可修改位置的情况下,仍能正确读取隐藏消息?并尽量多嵌入比特?
这等价于含缺陷单元的存储器写入问题 Writing in Memory with Defective Cells
写入者(机器)知道哪些存储单元是"卡死"的(stuck cells),但读取者不知道。
解决方式仍然可以是 Matrix Embedding,不过这次新增了一个约束,即湿区域的系数不能被修改。
Steganalysis¶
隐写分析本质上是二分类问题:判断一张图像是"载体图像"还是"隐写图像"。分析中有两类错误:
- 虚警(False Alarm):将正常图像误判为隐写图像(假阳性)
- 漏检(False Detection):将隐写图像误判为正常图像(假阴性)
性能评估通常用ROC曲线(接收者操作特征曲线)表示,横轴为假阳性率,纵轴为假阴性率,曲线越靠近左上角越好。
Sample Pairs Analysis¶
给定一个像素值序列 \(s_1, s_2, \ldots, s_n\),取所有相邻像素对:
实践中常取不重叠对:\((s_1,s_2),(s_3,s_4),\ldots,(s_{n-1},s_n)\)。
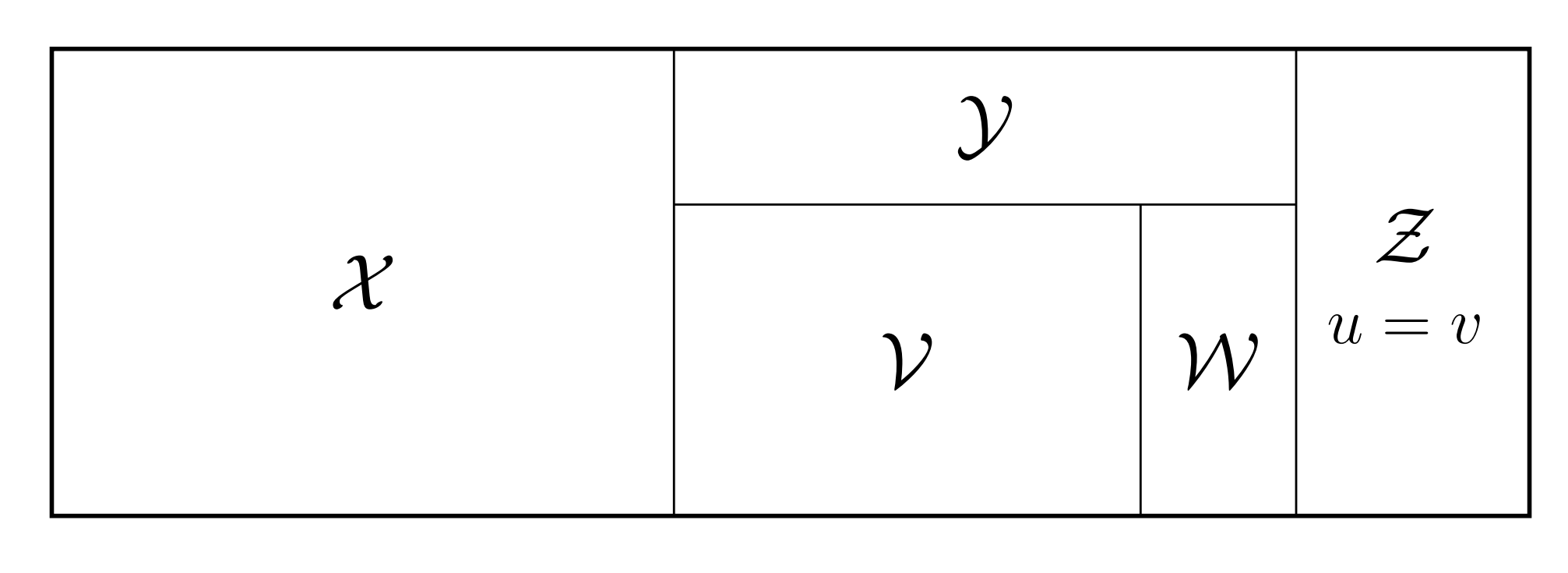
对 \(\mathcal{P}\) 中的每个对 \((u, v)\),按 \(v\) 的奇偶性和 \(u,v\) 大小关系进行分类:
| \(v\%2=0\) | \(v\%2=1\) | |
|---|---|---|
| \(u=v\) | \(\mathcal{Z}\) | \(\mathcal{Z}\) |
| \(u\lt v\) | \(\mathcal{X}\) | \(\mathcal{Y}\) |
| \(u\gt v\) | \(\mathcal{Y}\) | \(\mathcal{X}\) |
- \(\mathcal Z\):相等对,两像素值完全相同
- \(\mathcal{X}\):\(v\) 为偶且 \(u\lt v\),或 \(v\) 为奇且 \(u\gt v\)
- \(\mathcal{Y}\):\(v\) 为偶且 \(u\gt v\),或 \(v\) 为奇且 \(u\lt v\)
- \(\mathcal Y\) 被进一步划分为 \(\mathcal W\) 和 \(\mathcal V\)
- \(\mathcal W = \{(u=2k,v=2k+1)\lor (u=2k+1,v=2k), k\in \mathbf Z\}\)
- 或者可以说 \(|u-v|=1\)
- \(\mathcal V = \mathcal Y - \mathcal W\)
统计上,\(\mathcal X\) 和 \(\mathcal Y\) 的大小是近似相等的,\(\mathcal{P}\) 的 Partition 大致如下:
对于 \((u,v)\),根据 Modification Patterns 的不同,我们可以绘制如下的状态机:
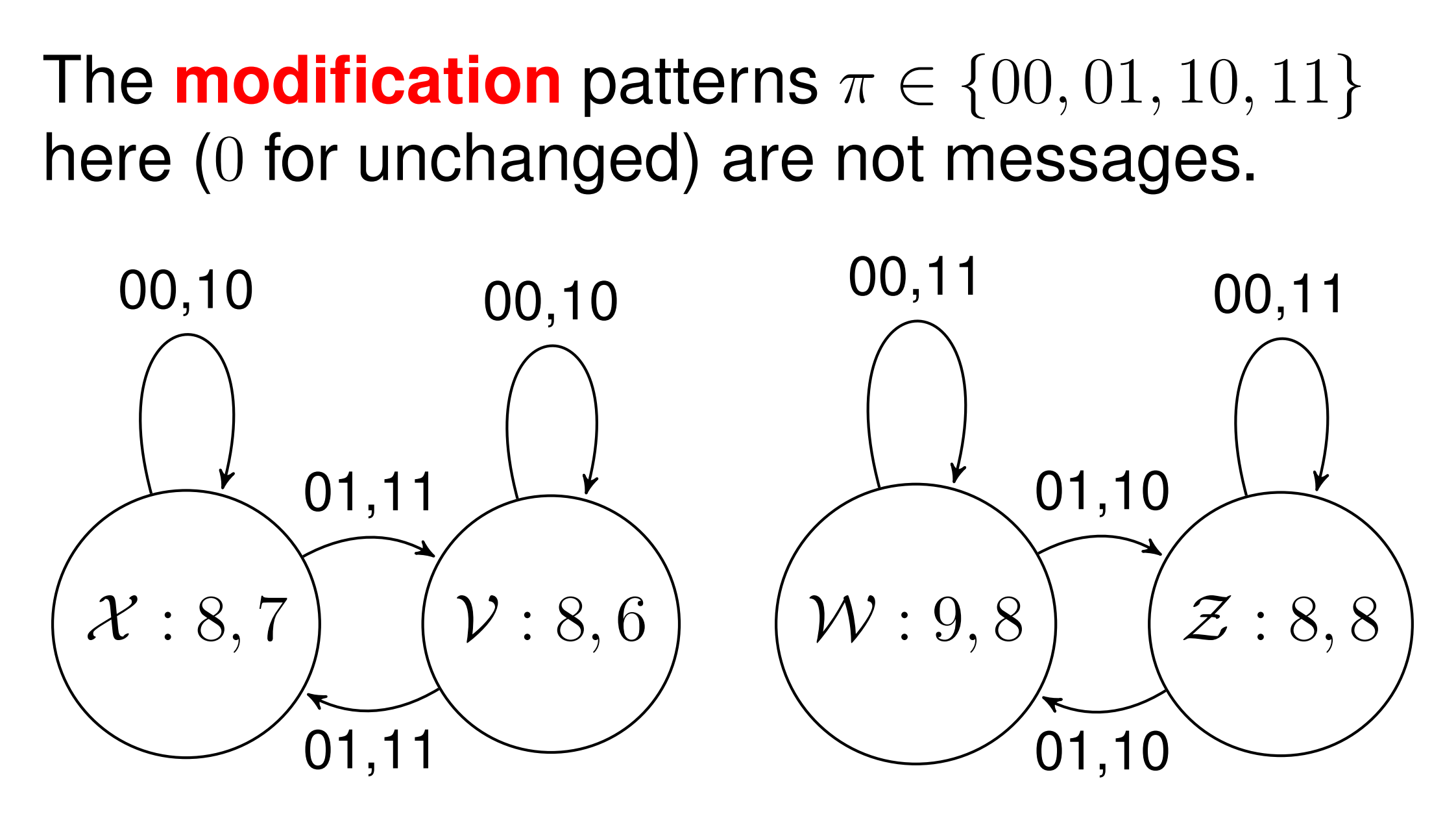
假设 \(m\) 为消息比特数,\(n\) 为载体像素数,\(q=m/n\) 为相对消息长度,则每一个 Modification 发生的概率为 \(q/2\),则各修改模式的概率为:
由此得到各类转移概率的合并:
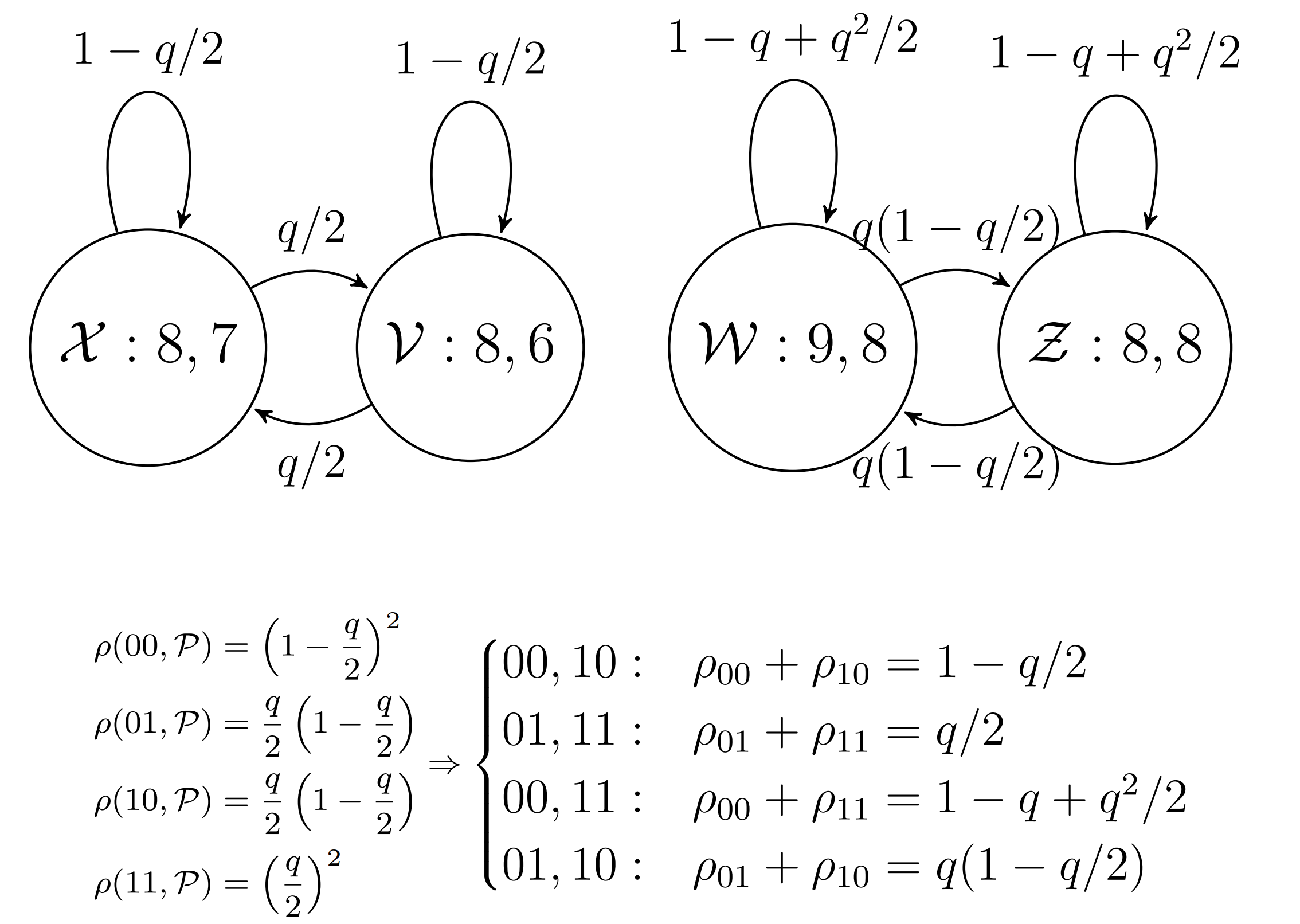
根据转移概率,计算嵌入后各集合的期望大小:
$\(\begin{array}l |\mathcal{X}'| = |\mathcal{X}|(1-q/2) + |\mathcal{V}|q/2 \\ |\mathcal{V}'| = |\mathcal{V}|(1-q/2) + |\mathcal{X}|q/2 \\ |\mathcal{W}'| = |\mathcal{W}|(1-q+q^2/2) + |\mathcal{Z}|q(1-q/2) \end{array}\)$ 为了分析求解得到 \(q\),我们做如下变换,从而得到关于 \(q\) 的一元二次方程:
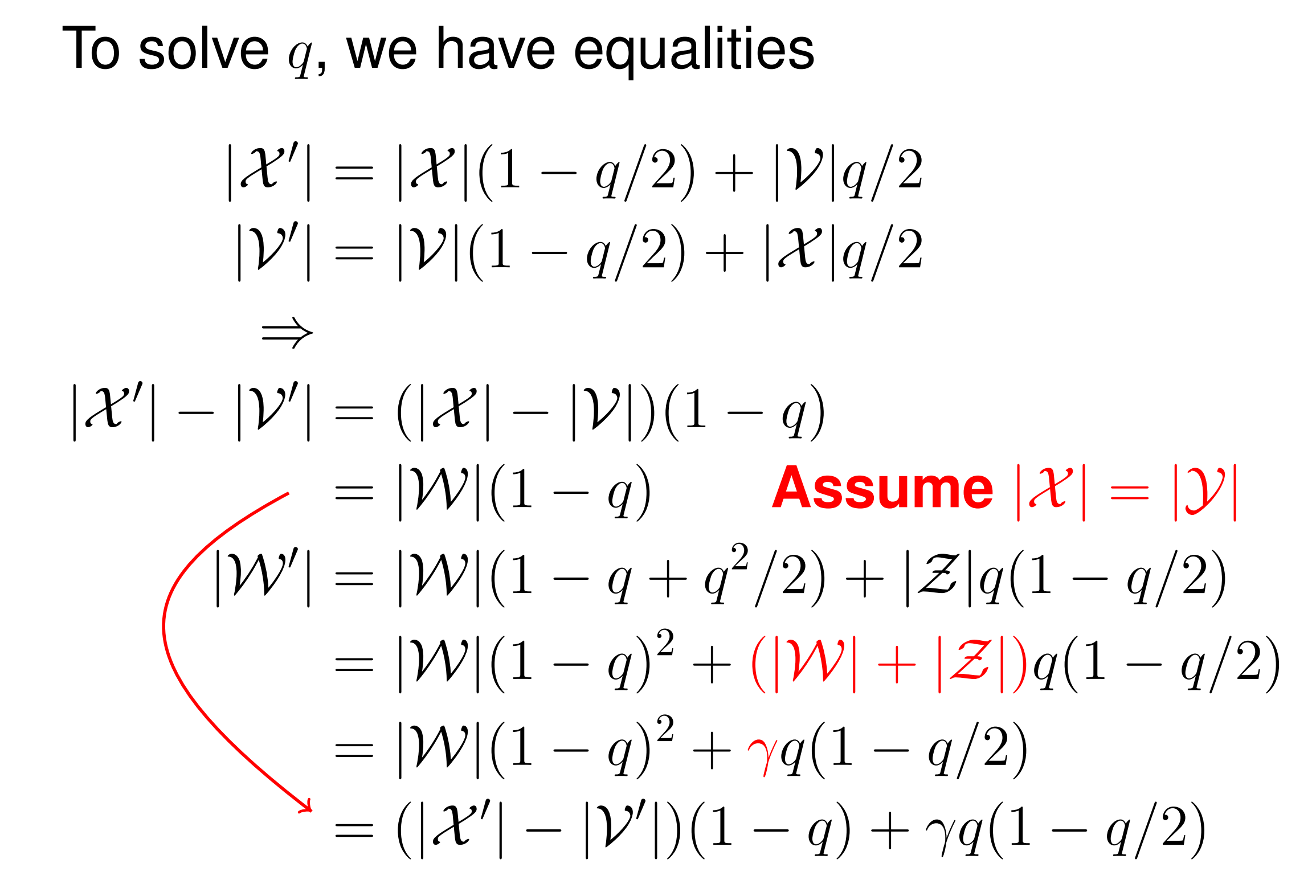
其中 \(\gamma = |\mathcal{W}| + |\mathcal{Z}| = |\mathcal{W}'| + |\mathcal{Z}'|\)(LSB bin的大小,嵌入前后不变)。
解一元二次方程,处理各种边界情况:
- 若 \(\gamma = 0\):退化为 \(0=0\),无法估计
- 若出现两个复共轭根:取实部作为估计
- 若出现负根:令 \(p=0\)(表示未嵌入消息)
- 取两个实根中在 \([0,1]\) 范围内、更合理的那个
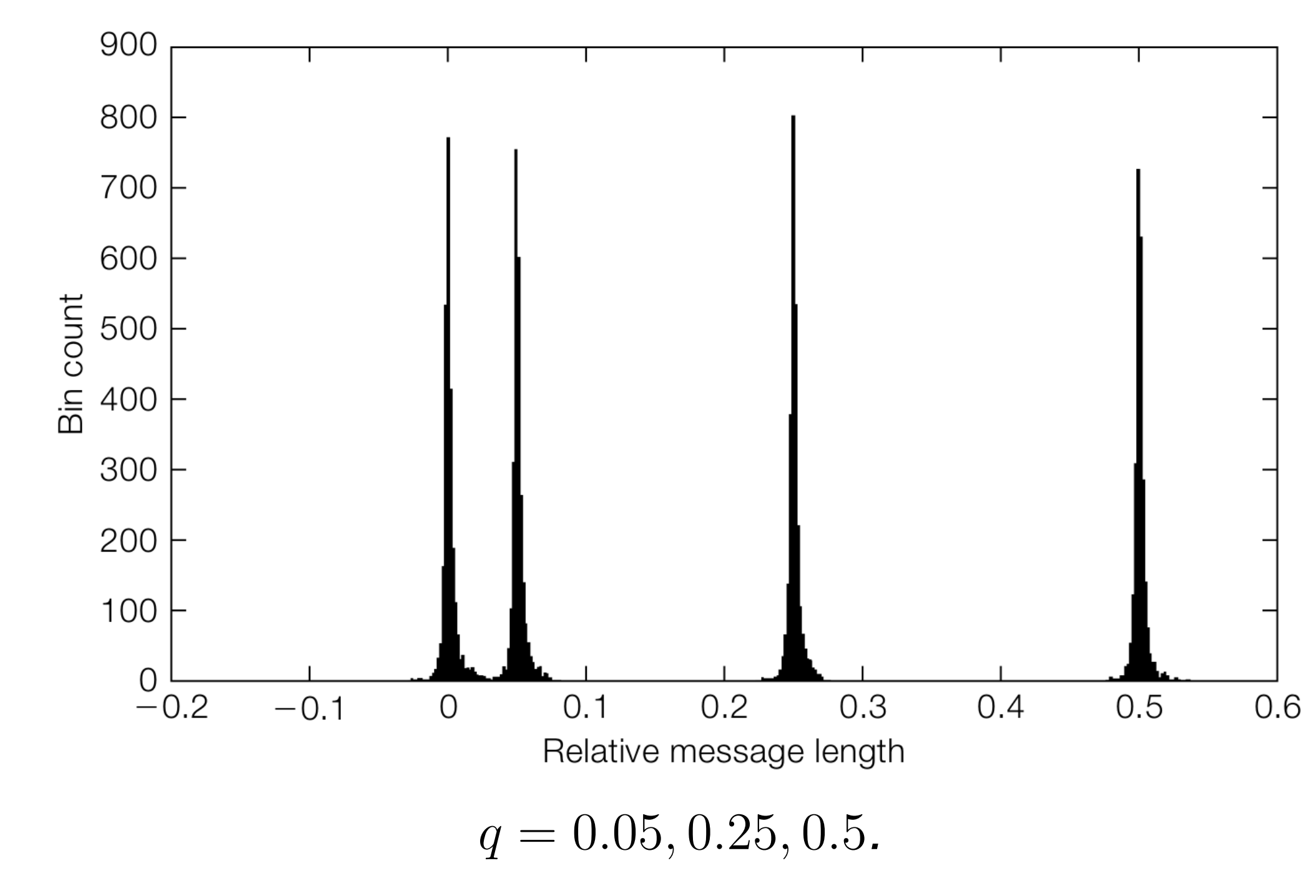
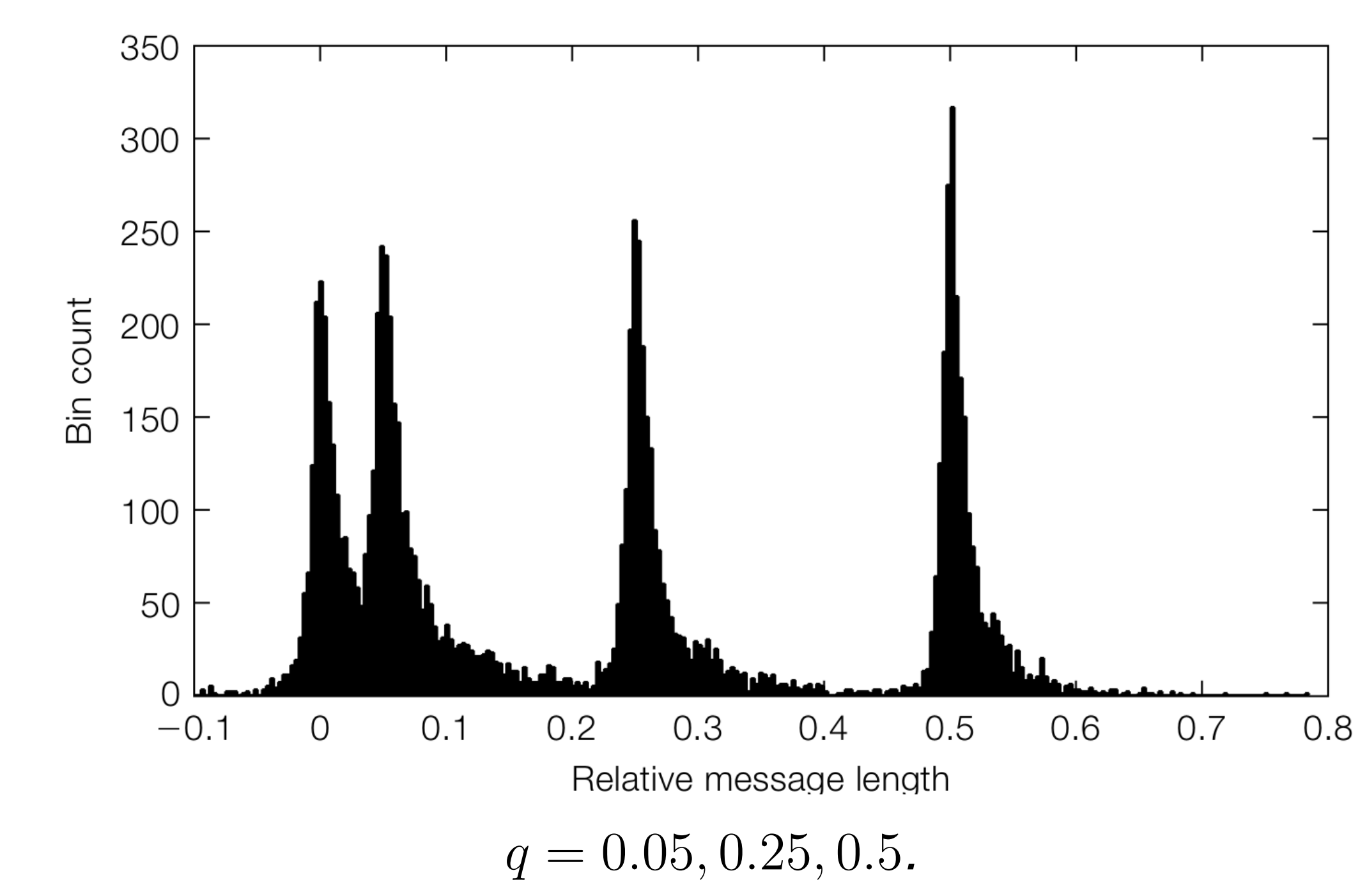
实验结果分析
- JPEG图像:对 \(q=0.05, 0.25, 0.5\) 的估计值分布非常集中于真实值附近,估计精度高
- 原始扫描图像:估计分布有一定展宽,精度略低,因为扫描图像噪声更大
- 分析:图像噪声对短消息的估计影响更大;局部相邻对(neighboring pairs)比全局样本对效果更好,因为局部相关性更强
Blind Steganalysis Using Calibration¶
无法直接获得原始载体图像时,通过将隐写图像平移4像素后重新压缩来近似估计原始载体的统计特征。
对JPEG图像,平移4像素恰好改变了DCT块的划分边界,重压缩后得到 \(J_2\),其统计特性近似于未经隐写的图像,可作为"参考"。
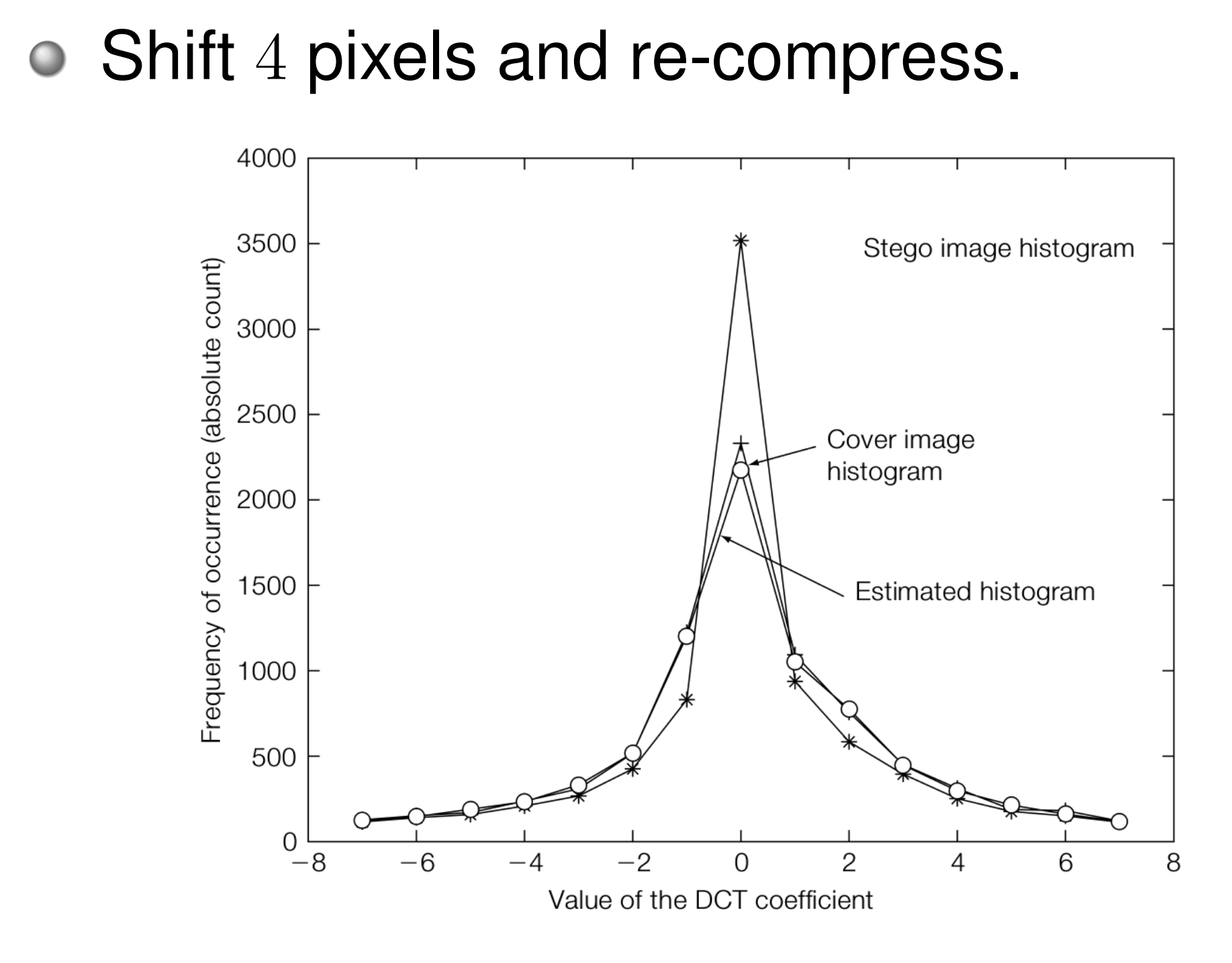
其中 \(J_1\) 是隐写图像,\(J_2\) 是平移重压缩后的图像,\(F_i\) 是各种统计特征函数。
若 \(f_i\) 足够大,则说明 \(J_1\) 的统计特征异常,存在隐写。特征 \(F_i\) 可以是DCT系数直方图、共生矩阵等。通过训练或手工设计找到对隐写最敏感的 \(F_i\)。